Un lanzamiento arriesgado suele parecer lo mismo. La code pasó la revisión, la compilación tuvo éxito y el equipo fusionó con confianza. Luego, el tráfico de producción golpea el nuevo camino de golpe, el soporte comienza a ver errores y tu única opción de devolución es otro despliegue bajo presión.
Este patrón de lanzamiento se descompone aún más rápido en aplicaciones híbridas. Su backend puede moverse rápidamente, pero su Capacitor o cliente de Electron puede seguir dependiendo del JavaScript enviado, la lógica de interfaz de usuario y los activos empaquetados que los usuarios ya tienen en el dispositivo. Si quieres una entrega más segura, necesitas una capa de control de tiempo de ejecución entre “code existe” y “los usuarios lo ven.”
Esa es donde las banderas de características ganan su valor. Les permiten enviar code en modo oscuro, exponerlo a cohortes específicas y apagarlo rápidamente cuando la realidad no coincide con las pruebas locales. Si estás trabajando en staged rollouts versus full releases en la entrega de aplicaciones, las banderas de características son el mecanismo que hace que los despliegues escalonados sean operativos en lugar de aspiracionales.
Contenido de la Tabla
- Introducción De lanzamientos arriesgados a despliegues controlados
- Elegir la arquitectura de la bandera de características
- Patrones de implementación básicos para aplicaciones de múltiples plataformas
- Lanzamientos estratégicos y targeting de audiencia
- Pruebas de observabilidad y higiene de banderas
- Automatizar y superar las banderas con CI/CD y actualizaciones en vivo
Introducción De lanzamientos arriesgados a lanzamientos controlados
La pregunta de cómo implementar banderas de características rara vez se plantea de manera proactiva. En su lugar, surge después de un lanzamiento doloroso.
Una reescritura de pago se pone en vivo para todos. Una pantalla de ajustes funciona en web pero se rompe en un build de escritorio. Una caja de concha móvil carga correctamente, pero el cliente code detrás de una nueva pestaña tiene casos de borde que nadie vio en staging. El problema no es solo mal code. El problema es que el lanzamiento y la implementación se trataron como el mismo evento.
Las banderas de características solucionan eso separando esos dos momentos. Los equipos envían el code primero y evalúan la bandera en tiempo de ejecución a través de lógica condicional. Datadog describe claramente el patrón básico en su visión general de implementación de banderas de características: la aplicación verifica la configuración en tiempo de ejecución y envía a los usuarios al nuevo camino o al antiguo camino de respaldo. Eso es por qué las banderas son útiles para un lanzamiento gradual, un objetivo de cohorte y un deshabilitamiento instantáneo sin volver a implementar toda la aplicación.
Regla práctica: Si deshabilitar una característica arriesgada todavía requiere volver a implementar, todavía no has construido un sistema de banderas de características real.
Esto importa aún más en stacks híbridos. Tu servidor puede decidir quién debe ver una característica, pero tu cliente todavía necesita comportarse consistentemente en web, Capacitor, y Electron. Eso significa que el sistema de banderas no puede ser un afterthought oculto en componentes aleatorios. Tiene que convertirse en parte del diseño de lanzamiento.
Las equipos que lo hacen bien tratan las banderas como herramientas de operación. Los utilizan para bloquear el trabajo incompleto, liberar primero a los usuarios internos y recuperarse rápidamente cuando lo inesperado aparece en producción.
Elige la arquitectura antes de extender las banderas a través del código base. Si haces ese trabajo tarde, terminas debatiendo sobre desacuerdos entre el servidor, la aplicación web, la __CAPGO_KEEP_0__ consola y la compilación de Electron en lugar de debatir sobre la característica en sí.
Choose the architecture before you spread flags through the codebase. If you do that work late, you end up debugging disagreements between the server, the web app, the Capacitor shell, and the Electron build instead of debugging the feature itself.
El control de liberación comienza con una fuente de verdad
Un sistema de banderas de características solo es útil si la aplicación puede preguntar a una fuente confiable por la decisión actual y aplicarla consistentemente. En la práctica, los equipos híbridos suelen necesitar dos capas que trabajen juntas:
Un plano de control
- que define el estado de la bandera, las reglas de destino, el historial de auditoría y los interruptores de muerte Un camino de entrega
- que obtiene el __CAPGO_KEEP_0__ y la configuración correctos en el cliente adecuado rápidamente that gets the right code and configuration onto the right client quickly
That second part gets missed in generic flag tutorials. A server-side flag can hide a feature, but it cannot ship a patched client bundle to a broken Capacitor or Electron app. For hybrid releases, flags and live updates need to work together. The flag controls exposure. The update system delivers the exact client code that should sit behind that flag.
Para los equipos de React y híbridos que ya están trabajando en esa configuración, esto Guía para banderas de características de React para aplicaciones híbridas Muestra cómo la elección de la arquitectura afecta los límites de los componentes, el flujo de estado y la seguridad de la implementación.
Normalmente, se elige uno de tres modelos:
- Construir en casa
- Comprar una plataforma de SaaS
- Ejecutar un sistema de código abierto por sí mismo
La elección correcta depende de las restricciones operativas, no del gusto. Pregunte preguntas directas. ¿Necesita evaluación en servidor para respuestas API? ¿Necesita valores por defecto en línea en dispositivos móviles? ¿Necesita un panel de control para productos y soporte? ¿Necesita registros de auditoría para cambios regulados? ¿Puede su equipo operar SDKs, invalidación de caché y lógica de enrutamiento para cada cliente que envía?
Construir, comprar o autoalbergar
Esto es la tabla de decisión que usaría con un equipo que planea lanzamientos a través de web, Capacitor, y Electron.
| Factor | Construir (En Casa) | Comprar (SaaS) | Fuente Abierta (Auto-Hosted) |
|---|---|---|---|
| Control | Control total sobre la esquema, reglas de evaluación y almacenamiento de datos | Menos control de infraestructura, mayor madurez del producto | Control alto con un modelo de plataforma existente |
| Configuración inicial | Rápido para booleanos básicos, más lento una vez que agregue targeting y gobernanza | Usualmente el camino más rápido | Trabajo de configuración y integración moderado |
| Carga operativa | Su equipo es responsable de la disponibilidad, SDK comportamiento, auditoría y eliminación de banderas de caducidad | El proveedor se encarga de la mayoría de la plataforma | Su equipo es responsable de alojamiento, actualizaciones y confiabilidad |
| Objetivo de complejidad | A menudo infravalorado después de la primera solicitud de implementación interna | Disponible de serie | Disponible, pero todavía necesita operar y ajustar |
| Opción de aplicación híbrida | Puede ajustarse exactamente a su pila si también construye buenos caminos de entrega del cliente | Depende de la calidad de SDK y el comportamiento en línea | Buena opción si puede adaptar la plataforma a sus clientes |
| Mantenimiento a largo plazo | Más alto una vez que las banderas se conviertan en operaciones de lanzamiento | El costo de la suscripción reemplaza la propiedad de la plataforma | Reducir el costo de construcción, costo operativo continuo |
Aquí está el trade-off que sorprende a los equipos. Construir un servicio de bandera no es difícil. Construir un servicio de bandera que maneje la configuración de destino, el almacenamiento en caché local, la promoción de entornos, los registros de auditoría, la expiración de banderas y la evaluación consistente en servidor y cliente es un trabajo real de plataforma.
He visto equipos construir un sistema en casa funcional en un sprint. Seis meses después, estaban manteniendo pantallas de administración, lógica de sobrescritura para QA, comprobaciones de desviación por entorno y code personalizados para refrescar la configuración del cliente de manera segura después del lanzamiento de la aplicación. La primera versión resolvió booleanos. La segunda versión se convirtió en infraestructura de lanzamiento.
Las plataformas de código abierto y SaaS reducen esa carga, pero no eliminan sus preocupaciones específicas de híbrido. Todavía necesita decidir dónde se realiza la evaluación, durante cuánto tiempo los clientes pueden cachear resultados, qué hace la aplicación en línea y cómo recuperarse cuando un paquete de cliente ya está en dispositivos. Unleash presenta claramente las partes móviles en su visión general del sistema de banderas de características: una configuración madura incluye un servicio de administración, almacenamiento, APIs, SDKs y mecanismos de actualización.
Si su plan de rollback es “girar la bandera hacia abajo”, verifique que el cliente ya tenga un fallback seguro code. Si no lo tiene, pair las banderas con actualizaciones en vivo para que pueda deshabilitar la exposición y enviar una corrección sin esperar a una versión de tienda.
Eso es donde el ángulo híbrido cambia la decisión de arquitectura. Las banderas del lado del servidor responden a “¿quién debería ver esto?”. Los sistemas de actualización en vivo, como Capgo, responden a “¿qué code debería ese usuario ejecutar en este momento?”. Utilice ambos. Desarrolle una característica para usuarios internos con una bandera, envíe el paquete de cliente actualizado solo a ese cohorte, y amplíe la exposición a medida que la telemetría permanezca limpia. Ese patrón le da un control de radio de explosión más ajustado que las banderas solas.
Si construye en casa, mantenga el alcance estrecho y explícito. Defina un esquema de banderas, centralice las reglas de evaluación, agregue un panel de administración API, registre cada cambio y establezca una política de eliminación antes de que la primera bandera se envíe. Si compra, pruebe el comportamiento del SDK en condiciones de red malas y a lo largo de reinicios de la aplicación. Si se autoalquila, presupueste tiempo de ingeniería para actualizaciones, propiedad de llamada en vivo y trabajo de integración de cliente desde el primer día.
Patrones de implementación de la corteza para aplicaciones de múltiples plataformas
Una aplicación híbrida suele fallar en las fronteras, no en la definición de la bandera en sí misma.
El modo de falla común es familiar. Los code web leen un valor de bandera en el arranque, un plugin Capacitor verifica una copia cacheada más tarde y una ventana de Electron evalúa la misma bandera nuevamente con un contexto de usuario ligeramente diferente. Ahora la liberación es inconsistente entre plataformas y el rollback se convierte en adivinanza.

Comience simple, luego centralice rápido
Cada bandera de característica comienza como un __CAPGO_KEEP_1__ if/else:
if (flags.newCheckout) {
renderNewCheckout();
} else {
renderLegacyCheckout();
}Eso está bien para el primer commit. Deja de estar bien una vez el mismo flag se verifica en cinco lugares y cada capa lo interpreta de manera diferente.
El artículo de patrones de botones de características de Aún da la línea base correcta. Mantén la lógica de evaluación centralizada, y mantén las condicionales cerca de la orilla del flujo en lugar de extenderlas a través de componentes de bajo nivel. En aplicaciones de múltiples plataformas, los puntos de evaluación útiles son generalmente:
Configuración de solicitud del servidor
- para SSR, configuración de __CAPGO_KEEP_0__ o entrega de configuración inicial for SSR, API shaping, or initial config delivery
- después de cargar el contexto de identidad, dispositivo y entorno Límites de ruta o pantalla
- donde flujos enteros difieren por el estado del flag Evita evaluar el mismo flag en componentes anidados, puentes nativos y utilidades de ayuda. Ese patrón crea desviaciones rápidamente.
Evita evaluar el mismo flag en componentes anidados, puentes nativos y utilidades de ayuda. Ese patrón crea desviaciones rápidamente.
Tomar decisiones, no banderas brutas
Una implementación madura separa los valores de las banderas de los proveedores de las decisiones de la aplicación.
Su proveedor de banderas responde a preguntas de bajo nivel como newCheckout=trueSu aplicación debe consumir decisiones de nivel superior como showNewCheckout, enableDesktopSidebar, o allowBackgroundSync. Ese nivel es donde codificas las reglas de negocio, las restricciones de plataforma y el comportamiento de fallback.
Esta indirección adicional se paga rápidamente.
Mantiene limpios los componentes de React. Reduce la acoplamiento a uno SDK. También te da un lugar para responder a una pregunta que los equipos híbridos enfrentan constantemente: ¿este usuario tiene tanto la bandera como el cliente correcto code?
El último punto importa para Capacitor y Electron. Un servidor puede cambiar la exposición instantáneamente, pero el cliente todavía necesita code que puedan renderizar de manera segura la característica. Combinar la evaluación de banderas con la entrega de paquetes dirigidos es cómo cerrar esa brecha. La guía de Capgo a actualizaciones en tiempo real con segmentación de usuarios muestra el modelo operativo. Evalúa quién debe obtener la característica, luego envía la actualización de cliente correspondiente a ese grupo sin esperar a una revisión de la tienda de aplicaciones.
Un patrón práctico de TypeScript
Esta es una pauta que se escalona mejor que las comprobaciones crudas en componentes.
type UserContext = {
userId?: string;
country?: string;
plan?: 'free' | 'pro' | 'enterprise';
platform: 'web' | 'capacitor' | 'electron';
isInternal?: boolean;
};
type RawFlags = {
newCheckout: boolean;
desktopSidebarRedesign: boolean;
smartSync: boolean;
};
class FeatureFlagService {
constructor(private flags: RawFlags, private user: UserContext) {}
get decisions() {
return {
showNewCheckout: this.flags.newCheckout && this.user.plan !== 'free',
showDesktopSidebar: this.user.platform === 'electron' && this.flags.desktopSidebarRedesign,
enableSmartSync: this.flags.smartSync && this.user.country !== undefined,
};
}
}Evalué una vez cerca de la parte superior de la aplicación:
async function bootstrapApp() {
const user = await getUserContext();
const flags = await fetchFlagsForUser(user);
const featureService = new FeatureFlagService(flags, user);
const decisions = featureService.decisions;
startApp({ user, decisions });
}Luego mantén la interfaz de usuario tonta:
type AppProps = {
decisions: {
showNewCheckout: boolean;
showDesktopSidebar: boolean;
enableSmartSync: boolean;
};
};
function App({ decisions }: AppProps) {
return (
<>
{decisions.showDesktopSidebar ? <NewSidebar /> : <LegacySidebar />}
{decisions.showNewCheckout ? <CheckoutV2 /> : <CheckoutV1 />}
</>
);
}Esta estructura te da consistencia en varias pantallas, pruebas más simples y un camino de eliminación más limpio una vez que se complete el lanzamiento.
Agrega plataforma y estado de actualización a la capa de decisión
Las aplicaciones híbridas necesitan una comprobación adicional que los tutoriales de banderas genéricas a menudo omiten. Una característica no debe activarse solo porque la bandera remota dice sí. Debe activarse solo si el cliente instalado o actualizado en vivo puede soportarlo.
Por lo tanto, la capa de decisión a menudo necesita entradas más allá de banderas crudas:
- versión de la aplicación actual
- versión actualizada del paquete en vivo
- plataforma
- estado de línea de fondo
- diseño de capacidad nativa
A un objeto de decisión se puede expresar directamente:
type RuntimeContext = {
appVersion: string;
bundleVersion?: string;
isOffline: boolean;
hasNativeBiometrics: boolean;
};
function buildDecisions(flags: RawFlags, user: UserContext, runtime: RuntimeContext) {
return {
showNewCheckout:
flags.newCheckout &&
user.plan !== 'free' &&
runtime.bundleVersion === 'checkout-v2',
enableSmartSync:
flags.smartSync &&
!runtime.isOffline,
enableBiometricUnlock:
flags.smartSync &&
runtime.hasNativeBiometrics &&
user.platform === 'capacitor',
};
}Esta es la compensación práctica. La capa de decisión se vuelve más compleja, pero la aplicación se vuelve más segura de operar. Los equipos que omiten esta etapa suelen descubrir el vacío durante el rollback, cuando la bandera está apagada pero el code incompatible ya está activo en dispositivos, o la bandera está encendida para usuarios que nunca recibieron el paquete requerido.
Utilice la agrupación determinista para cualquier lógica de lanzamiento
La lógica de lanzamiento porcentual pertenece a un lugar también. No asignar usuarios aleatoriamente en cada renderizado o lanzamiento de la aplicación. Utilice un identificador estable y un hasheo determinista para que el mismo usuario quede en el mismo contenedor.
function isInRollout(featureName: string, userId: string, rolloutGate: number): boolean {
const bucket = stableHash(`${featureName}:${userId}`) % 100;
return bucket < rolloutGate;
}La función de hash exacta es menos importante que el comportamiento. El mismo input siempre debería aterrizar en el mismo contenedor. Si también se entregan actualizaciones en vivo, mantenga la entrada de agrupación alineada con las reglas de audiencia utilizadas para enviar paquetes. De lo contrario, puede exponer una bandera de característica a usuarios que nunca recibieron el code respaldante.
Una regla final ayuda a evitar una gran cantidad de limpieza posterior. Mantenga las comprobaciones de banderas fuera de componentes hoja reutilizables a menos que el componente exista solo para esa experimentación. Coloque la ramificación en la frontera de ruta, pantalla o servicio, y déjelo que el resto de la arborescencia renderice un solo camino elegido.
Despliegues Estratégicos y Trazado de Audiencia
A un plan de lanzamiento se le prueba por primera vez cuando el comportamiento de producción es diferente para un conjunto de usuarios que para otro. Un flujo de pago funciona en Electron de escritorio, falla en versiones antiguas de WebView de Android y el soporte necesita saber quién está expuesto en este momento. Eso es el punto donde una bandera booleana ya no es suficiente.

Una historia de lanzamiento para un nuevo flujo de pago.
Diga que estás enviando new-checkout en una aplicación Capacitor con una construcción de escritorio de Electron. El cambio de interfaz de usuario vive detrás de una bandera de servidor, pero parte de la lógica de apoyo se envía como cliente code. Si esos dos sistemas no están alineados, los usuarios pueden obtener la bandera antes de tener el paquete, o obtener el paquete antes de que deberían ver la característica.
Comienza con cuentas de personal y dispositivos de QA. Luego mueve a usuarios de beta opt-in en una plataforma, como solo Electron, mientras que el móvil sigue en el camino antiguo. Después de eso, expande por cohortes y porcentajes mientras observas las tasas de error, los rechazos de pago y los tickets de soporte. Mantén el pago antiguo accesible hasta que el lanzamiento haya sobrevivido al tráfico real en cada plataforma que soportes.
Una política práctica para esa característica se parece a esto:
- Primero el cohort de interno: desarrolladores, QA, soporte y cuentas de demo
- Usuarios de beta por plataforma: usuarios de acceso temprano, pero solo en las versiones de la aplicación y los entornos de ejecución en los que confías
- Producción en pasos: Aumenta la exposición en pequeñas cantidades y pausa en cualquier regresión
- Se mantiene vivo el fallback: El antiguo camino sigue siendo callable hasta que el nuevo camino esté estable en producción
Para aplicaciones híbridas, también necesita una política de entrega la política de rollout. Segmentación de actualizaciones en vivo para aplicaciones Capacitor Muestra cómo enviar el paquete de cliente correspondiente a las mismas cohortes que su sistema de banderas está apuntando. Esa conexión importa porque el control de la versión es débil si la bandera y el paquete code enviado siguen diferentes reglas de audiencia.
Las reglas de destino que se mantienen en producción
Las buenas reglas de destino utilizan atributos que puedes explicar y reproducir durante un incidente. Plataforma, versión de la aplicación, región, nivel de cuenta, estado de usuario interno y registro de beta son comunes porque suelen estar disponibles en el momento de la evaluación y son lo suficientemente estables para auditorías y soporte.
Las malas reglas de destino dependen de valores que aparecen tarde o cambian con frecuencia. El estado de sesión local, campos de perfil sincronizados parcialmente o propiedades solo del cliente crean desacoples difíciles de depurar entre lo que el servidor pretendió y lo que la aplicación renderizó.
Usa reglas que tu equipo pueda leer sin abrir tres tableros. internal, beta_mobileLos atributos enterprise_desktop_v2 son más fáciles de operar que los IDs de segmento anónimos. El soporte debe poder responder a una pregunta rápidamente: ¿por qué este usuario recibió esta característica?
Una otra compensación que vale la pena hacer explícita. La configuración de destino propiedad del servidor mantiene la política centralizada, pero las aplicaciones híbridas todavía necesitan suficiente contexto del cliente para aplicar recaídas locales seguras cuando la red es lenta o inalcanzable. El patrón habitual es dejar que el servidor decida la exposición y que el cliente aplique comprobaciones de compatibilidad, como tiempo de ejecución, versión del paquete o capacidad nativa.
Las palancas de muerte son parte del diseño
Una palanca de muerte es parte del diseño de la versión desde el primer día. No es trabajo de limpieza para más tarde.
Para características de clientes, mantenga el camino anterior activo hasta que el nuevo haya pasado tráfico de producción real a través de sus cohortes principales. Si los errores de pago de la cesta aumentan para una región o una ejecución, debería poder deshabilitar la característica para ese público inmediatamente sin tener que esperar a una revisión de la tienda de aplicaciones.
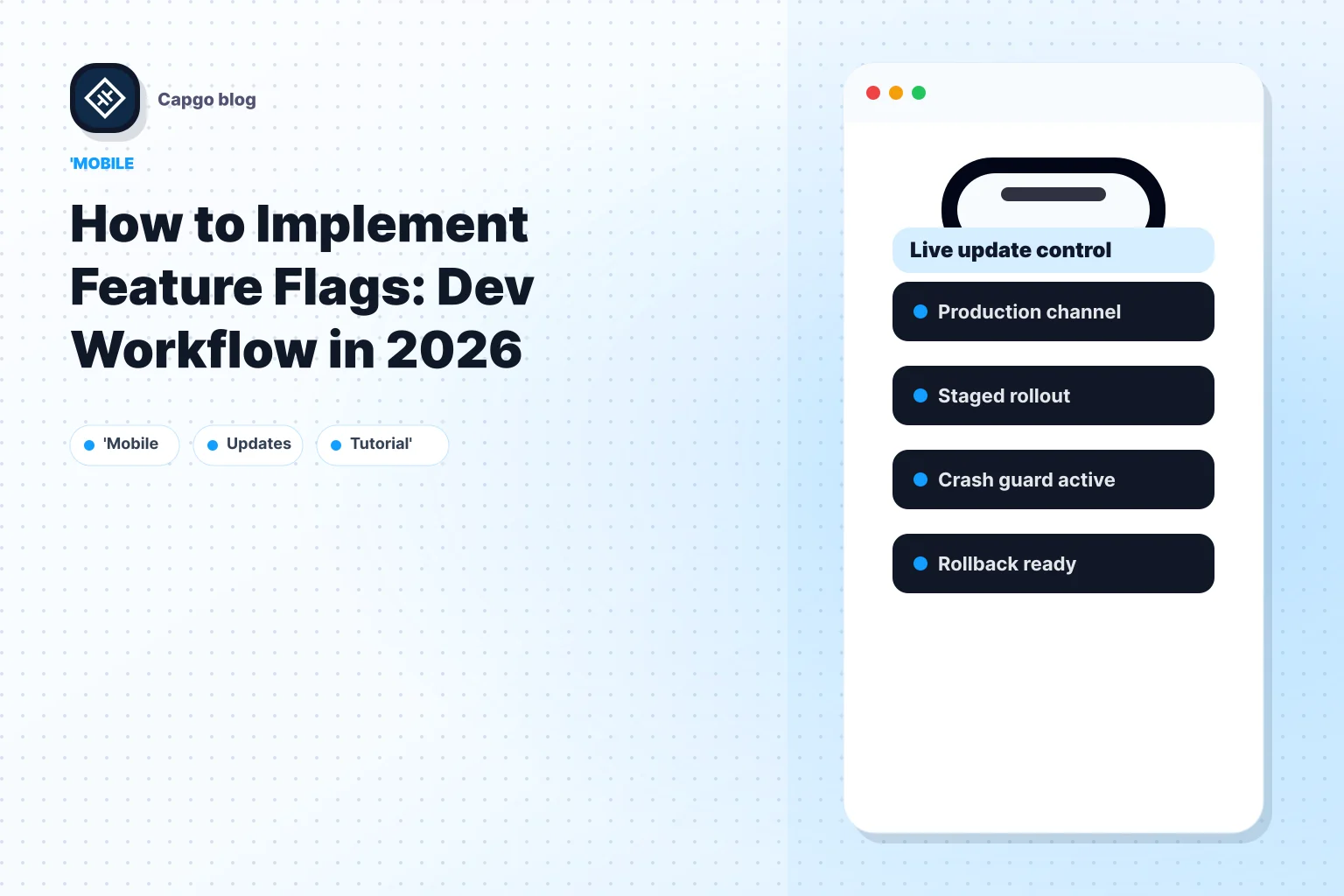
Las aplicaciones híbridas agregan otra capa. Una bandera del lado del servidor puede ocultar un camino roto, pero no puede reparar code ya instalado en dispositivos. Los sistemas de actualización en vivo, como Capgo, cierran esa brecha. Puede desactivar la característica, luego enviar un paquete corregido a la cohorte afectada en lugar de esperar al próximo ciclo de lanzamiento completo.
Esa combinación es lo que hace que los lanzamientos sean operativos en lugar de teóricos. Las banderas controlan la exposición. La configuración de destino limita el radio de explosión. Las actualizaciones en vivo reparan rápidamente al cliente cuando el comportamiento de tiempo de ejecución y los code enviados se desvían.
Prueba Observabilidad y Higiene de Bandera
A la bandera de una característica le agregan code rutas, problemas de tiempo y estado que ahora debes razonar en producción. Si no pruebas y observas ese estado directamente, la bandera desplaza el riesgo en lugar de reducirlo.
Prueba ambos ramales a propósito
Trata cada bandera como dos lanzamientos viviendo en el mismo código base. La ruta antigua todavía necesita protección mientras que la nueva ruta se despliega, y la nueva ruta necesita pruebas de que se comporta correctamente bajo condiciones de aplicación reales.
En el nivel de unidad, inyecta la decisión de la bandera para que las pruebas sigan siendo determinísticas. En el nivel de integración y final, da a QA y CI un override controlado. No confíes en las reglas de targeting en vivo durante una ejecución de prueba. Esa regla cambia, las cachés caducan y de repente un test flaco te está diciendo más sobre el tiempo de despliegue que sobre el comportamiento del producto.
Para aplicaciones híbridas, prueba los momentos en que el estado de la bandera puede deslizarse desde el estado de la aplicación:
- Rutas habilitadas y deshabilitadas: mantén la cobertura en ambos hasta que se elimine la bandera.
- Cohortes de límite: verifica las reglas de empleado, beta, pago, regional y usuario anónimo por separado.
- Lanzamiento, reanudación y flujo de refresco: muchos Capacitor y aplicaciones Electron reevalúan el estado en esos puntos.
- Comportamiento de fallback en línea: confirme que el cliente utiliza la última decisión conocida buena o un valor por defecto seguro cuando la red no está disponible.
- Compatibilidad de paquetes: Si una bandera expone code entregado a través de una actualización en vivo, verifique que la aplicación no habilite la interfaz de usuario que el paquete actual no puede soportar.
Es fácil pasar por alto ese último punto. Un servidor puede decidir que un usuario debe ver una característica, pero el cliente todavía tiene que confirmar que el paquete instalado y el runtime nativo pueden ejecutarla de manera segura.
Observa la bandera, no solo la característica
La instrumentación debe permitirte responder a tres preguntas rápidamente. ¿Quién vio la bandera? ¿Qué code ruta se ejecutó? ¿Qué versión de paquete estaba activa cuando se ejecutó?
A menudo, los equipos configuran la bandera y se detienen allí. Luego, una picada de errores aparece en producción y nadie puede determinar si el problema vino de la bandera marcada code, un segmento de audiencia o un cliente de paquete obsoleto. La solución es sencilla. Agrega el estado evaluado de la bandera a los eventos de análisis, registros, trazas y informes de errores. No registre solo feature=new_checkoutRegistra la decisión real, la regla o cohorte que la produjo y la versión del cliente que la ejecutó.
Un formato de evento simple suele ser suficiente:
{
"event": "checkout_started",
"flag_new_checkout": true,
"flag_rule": "beta_users_us",
"app_version": "5.4.1",
"bundle_version": "2026.06.13-2",
"platform": "capacitor-ios"
}Esta estructura hace que el depurado en producción sea mucho más rápido. Puedes separar una regla de lanzamiento mala de un paquete malo, y puedes ver si una plataforma está fallando mientras otra está sana.
Para aplicaciones híbridas métricas de actualización en tiempo real para aplicaciones Capacitor cerrar la brecha entre el control de liberación y la evidencia de tiempo de ejecución. Cuando combinás los datos de exposición de características con los datos de adopción de paquetes, puedes determinar si una regresión provino de la decisión de la bandera, el JavaScript enviado, o la interacción entre los dos.
Una bandera sin observabilidad es complejidad oculta con una casilla de cuadro de la consola adjunta.
La limpieza es parte de la implementación
La deuda de banderas se convierte rápidamente en deuda de code.
Las banderas peores son las exitosas que nadie eliminó. Mantienen ramas muertas vivas, confunden a los ingenieros de incorporación, y expanden la matriz de pruebas mucho después de que la decisión de lanzamiento esté sobre.
Establecer reglas de higiene cuando se crea la bandera:
- Asignar un propietario.
- Grabar la condición de eliminación.
- Abrir la tarea de limpieza inmediatamente.
- Eliminar los code muertos tan pronto como la liberación esté completa.
- Archivar o eliminar la entrada de la bandera para que el soporte y la ingeniería no la traten como activa todavía.
También recomiendo una regla práctica para los equipos que envían a través de banderas del lado del servidor más actualizaciones en vivo. Si una bandera existe solo para proteger una migración corta entre paquetes de cliente antiguos y nuevos, dale una fecha de expiración corta y reviséla con el propietario de la liberación, no como limpieza de backlog general. Las banderas temporales se multiplican rápidamente en Capacitor y aplicaciones de Electron, especialmente cuando estás parcheando el comportamiento de producción sin esperar a una liberación completa de la tienda.
Automatizando y Superando Flags con CI/CD y Actualizaciones en Vivo
Los flujos de trabajo de banderas manuales no se escalan bien. También fallan en el peor momento, generalmente durante un parche de emergencia.
Una configuración madura vincula las banderas al mismo proceso de entrega que compila, prueba y envía la aplicación.

Hacer la creación de banderas parte del proceso de entrega
Cuando una rama de características se fusiona, su pipeline ya debería saber lo suficiente para crear o validar la bandera que la protegerá. Eso no significa que cada commit necesite una nueva palanca. Significa que el control de lanzamiento debería ser sistemático, no conocimiento tribal que tenga quien fusionó último.
La automatización útil suele incluir:
- Verificación de esquemas de banderas: verificar nombres, propietarios y planes de vencimiento antes de fusionar.
- Predeterminados de entorno: Las nuevas características riesgosas deben comenzar deshabilitadas en producción a menos que se aprueben explícitamente.
- Notas de lanzamiento con estado de bandera: necesitan saber qué características están bloqueadas en la compilación.
- Recordatorios de limpieza: las banderas antiguas deben surgir en el flujo de trabajo de ingeniería antes de convertirse en un desorden permanente.
Si está integrando esto en las pipelines de despliegue móvil y híbrido, configurar CI/CD para aplicaciones Capacitor es el lado operativo del mismo problema.
Dónde las actualizaciones en vivo cambian la ecuación
Las aplicaciones híbridas necesitan un libro de estrategias diferente de las aplicaciones web puras.
Una bandera del lado del servidor decide quién debe ver una característica. Pero a veces, el code detrás de esa característica necesita cambiar después de que el binario de la aplicación ya está en manos de los usuarios. En Capacitor y Electron, eso crea una brecha de lanzamiento. La bandera puede ocultar o exponer un camino, pero no puede reescribir el paquete del cliente por sí sola.
Eso es por qué los sistemas de actualizaciones en vivo se parecen tan bien con las banderas de características. La bandera controla quién debe ver la característica. El canal de actualización controla que cliente code aquellos usuarios reciben. Por ejemplo, un equipo podría utilizar LaunchDarkly o Unleash para el objetivo de tiempo de ejecución y utilizar Capgo para entregar JavaScript actualizado, CSS, copia, configuración y activos a canales específicos en una aplicación Capacitor o Electron sin esperar a la revisión de la tienda.
Esa combinación es especialmente efectiva para el lanzamiento dirigido en entornos híbridos:
- Objetivo de servidor: seleccione al público en tiempo de ejecución.
- Entrega de cliente: envíe el conjunto exacto que apoya la característica.
- Recuperación operativa: desactive la característica, envíe un conjunto reparado o ambos.
- Consistencia de plataforma: mantenga la lógica de liberación de web, escritorio y móvil alineada incluso cuando los mecanismos de entrega difieren.
Esta guía ofrece una visión concreta de cómo los equipos manejan ese flujo de trabajo en la práctica:
Si está seriamente comprometido con la implementación de banderas de características en una pila híbrida, piense en capas. Una capa decide la exposición. Otra entrega code. Una tercera observa qué sucedió. Cuando esas capas están separadas pero coordinadas, las liberaciones dejan de sentirse como apuestas irreversibles y comienzan a comportarse como operaciones controladas.
Capgo se ajusta a esa segunda capa para los equipos que envían aplicaciones de CapacitorJS y Electron. Proporciona actualizaciones en vivo, targeting basado en canales, controles de rollback, observabilidad y integración CI/CD para la entrega de paquetes web, lo que lo convierte en un complemento práctico a un sistema de banderas de características de servidor cuando su estrategia de liberación depende tanto del control en tiempo de ejecución como de reparaciones rápidas en el lado del cliente.


