Un rilascio rischioso sembra sempre lo stesso. Il code ha superato la revisione, la compilazione è riuscita e il team ha unito con fiducia. Poi il traffico di produzione colpisce il nuovo percorso tutto insieme, il supporto inizia a vedere gli errori e la tua unica opzione di rollback è un altro deploy sotto pressione.
Quel modello di rilascio si rompe ancora più velocemente negli app ibride. Il tuo backend può muoversi velocemente, ma il tuo Capacitor o Electron client può ancora dipendere dal JavaScript spedito, dalla logica di interfaccia utente e dagli asset incorporati che gli utenti già hanno sul dispositivo. Se vuoi una consegna più sicura, hai bisogno di un layer di controllo runtime tra “code esiste” e “gli utenti lo vedono”.
Ecco dove le bandiere di feature guadagnano il loro valore. Consentono di spedire code in modalità oscura, di esporlo a specifiche cohort e di disattivarlo velocemente quando la realtà non corrisponde ai test locali. Se si sta lavorando attraverso la differenza tra rilasci in fase di testing e rilasci completi nella consegna di applicazionile bandiere di feature sono il meccanismo che rende il rilascio in fase di testing operativo invece di essere solo un obiettivo.
Tavola dei contenuti
- Introduzione Dai rilasci rischiosi ai rilasci controllati
- Scegliere l'architettura delle bandiere di feature
- Modelli di implementazione di base per applicazioni cross-platform
- Rollout Strategici e Targeting di Pubblico
- Testabilità, osservabilità e igiene delle bandiere
- Automazione e superamento delle bandiere con CI/CD e aggiornamenti in tempo reale
Introduzione Dai rilasci a rischio ai rilasci controllati
La domanda su come implementare le bandiere di feature non viene chiesta proattivamente. Invece, emerge dopo un rilascio doloroso.
Un riavvio del checkout va in live per tutti. Uno schermo di impostazioni funziona su web ma si rompe su un build desktop. Una shell mobile carica bene, ma il client code dietro una nuova scheda ha casi d'edge che nessuno ha visto in staging. Il problema non è solo cattivo code. Il problema è che il rilascio e la distribuzione sono stati trattati come lo stesso evento.
Le bandiere di feature risolvono questo problema separando quei due momenti. Le squadre inviano il code per primo e valutano la bandiera in esecuzione attraverso logica condizionale. Datadog descrive il pattern di base chiaramente nel suo resoconto di implementazione delle bandiere di feature: l'applicazione controlla la configurazione in esecuzione e invia gli utenti sulla nuova strada o sulla vecchia strada di fallback. È per questo che le bandiere sono utili per il rilascio graduale, la targeting di cohort e l'annullamento istantaneo senza riavviare l'intera app.
Regola pratica: Se disabilitare una feature a rischio richiede ancora un riavvio, non hai ancora costruito un sistema di bandiere di feature reale.
Ciò è ancora più importante in stack ibridi. Il tuo server può decidere chi dovrebbe vedere una feature, ma il tuo client deve comportarsi in modo coerente su web, Capacitor, e Electron. Ciò significa che il sistema delle bandiere non può essere un dopo pensiero nascosto all'interno di componenti random. Deve diventare parte del tuo design di rilascio.
Le squadre che lo fanno bene trattano le bandiere come strumenti di gestione operativa. Utilizzano le bandiere per bloccare il lavoro incompleto, rilasciare prima ai utenti interni e recuperare rapidamente quando si verifica qualcosa di imprevisto in produzione.
Scegliere l'architettura delle bandiere del tuo feature
Scegli l'architettura prima di diffondere le bandiere nel codice. Se fai questo lavoro in ritardo, finisci per debuggare le disaccordi tra il server, l'app web, la shell Capacitor e l'app Electron invece di debuggare la feature stessa.
La decisione chiave è semplice. Dove vive la verità delle bandiere e chi la valuta?
Il controllo di rilascio inizia con una fonte di verità
Un sistema di bandiere di feature è utile solo se l'app può chiedere a una fonte affidabile la decisione corrente e applicarla in modo coerente. In pratica, le squadre ibride solitamente hanno bisogno di due layer che lavorano insieme:
- Un piano di controllo che definisce lo stato delle bandiere, le regole di targeting, la storia degli audit e i pulsanti di arresto
- Un percorso di consegna che ottiene il code e la configurazione giusta sul client giusto velocemente
That second part gets missed in generic flag tutorials. A server-side flag can hide a feature, but it cannot ship a patched client bundle to a broken Capacitor or Electron app. For hybrid releases, flags and live updates need to work together. The flag controls exposure. The update system delivers the exact client code that should sit behind that flag.
Per le squadre React e ibride che già lavorano su quel setup, questo Guida alle feature flags per React per applicazioni ibride Mostra come la scelta dell'architettura influisce sui confini dei componenti, il flusso di stato e la sicurezza del rilascio.
Di solito, si sceglie uno dei tre modelli:
- Costruisci in-house
- Acquista una piattaforma SaaS
- Esegui un sistema open-source da solo
La scelta giusta dipende dalle restrizioni operative, non dal gusto. Chiedi domande dirette. Hai bisogno di valutazioni server-side per le risposte API? Hai bisogno di impostazioni di default offline su dispositivi mobili? I prodotti e il supporto hanno bisogno di un dashboard? Hai bisogno di registrazioni di audit per modifiche regolate? Il tuo team può gestire gli SDK, l'invalidazione della cache e la logica di targeting per ogni cliente che spedisci?
Costruisci, compra o ospita da solo
Ecco la tabella di decisione che utilizzerei con un team che pianifica rilasci su web, Capacitor, e Electron.
| Fattore | Costruisci (In-House) | Compra (SaaS) | Open Source (Self-Hosted) |
|---|---|---|---|
| Controllo | Pieno controllo sullo schema, sulle regole di valutazione e sullo storage dei dati | Menore controllo sull'infrastruttura, maggiore maturità del prodotto | Alto controllo con un modello di piattaforma esistente |
| Impostazione iniziale | Rapido per booleani base, più lento quando si aggiungono targeting e governance | Solitamente il percorso più veloce | Lavoro di configurazione e integrazione moderato |
| Carico operativo | Il tuo team è responsabile della disponibilità, del comportamento di SDK, della tracciabilità e della pulizia del flag di obsolescenza | Il fornitore gestisce la maggior parte della piattaforma | Il tuo team è responsabile dell'hosting, degli aggiornamenti e della affidabilità |
| Target di complessità | Spesso sottovalutato dopo la prima richiesta di rollout interna | Di solito disponibile a scelta | Disponibile, ma ancora devi operare e regolare |
| Adatto per applicazioni ibride | Può corrispondere alla tua pila esattamente se anche costruisci buone vie di consegna del client | Dipende dalla qualità di SDK e dal comportamento offline | Buona scelta se puoi adattare la piattaforma ai tuoi clienti |
| Manutenzione a lungo termine | Più alta una volta che le bandiere di rilascio diventano parte delle operazioni di rilascio | Il costo della sottoscrizione sostituisce la proprietà della piattaforma | Riduci il costo di costruzione, il costo operativo in corso |
Ecco il trade-off che coglie le squadre alla sprovvista. Costruire un servizio di flag non è difficile. Costruire un servizio di flag che gestisce la targeting, il caching locale, la promozione dell'ambiente, i registri di audit, la scadenza delle flag e l'evaluazione coerente su server e client è un lavoro di piattaforma reale.
Ho visto squadre costruire un sistema funzionante in-house in un sprint. Sei mesi dopo, stavano mantenendo schermate di amministrazione, logica di override per la QA, controlli di deriva per ambiente e code personalizzati per rinfrescare la configurazione del client in modo sicuro dopo l'avvio dell'app. La prima versione risolveva booleani. La seconda versione divenne infrastruttura di rilascio.
Le piattaforme open-source e SaaS riducono quel carico, ma non eliminano le vostre preoccupazioni specifiche per l'ibrido. Avete ancora bisogno di decidere dove avviene l'evaluazione, per quanto tempo i clienti possono memorizzare i risultati, cosa fa l'app in modalità offline e come recuperare quando un bundle del client è già sulle dispositivi. Unleash espone chiaramente le parti in movimento nella sua visuale del sistema di flag: una configurazione matura include un servizio di gestione, un archivio, API, SDK e meccanismi di aggiornamento.
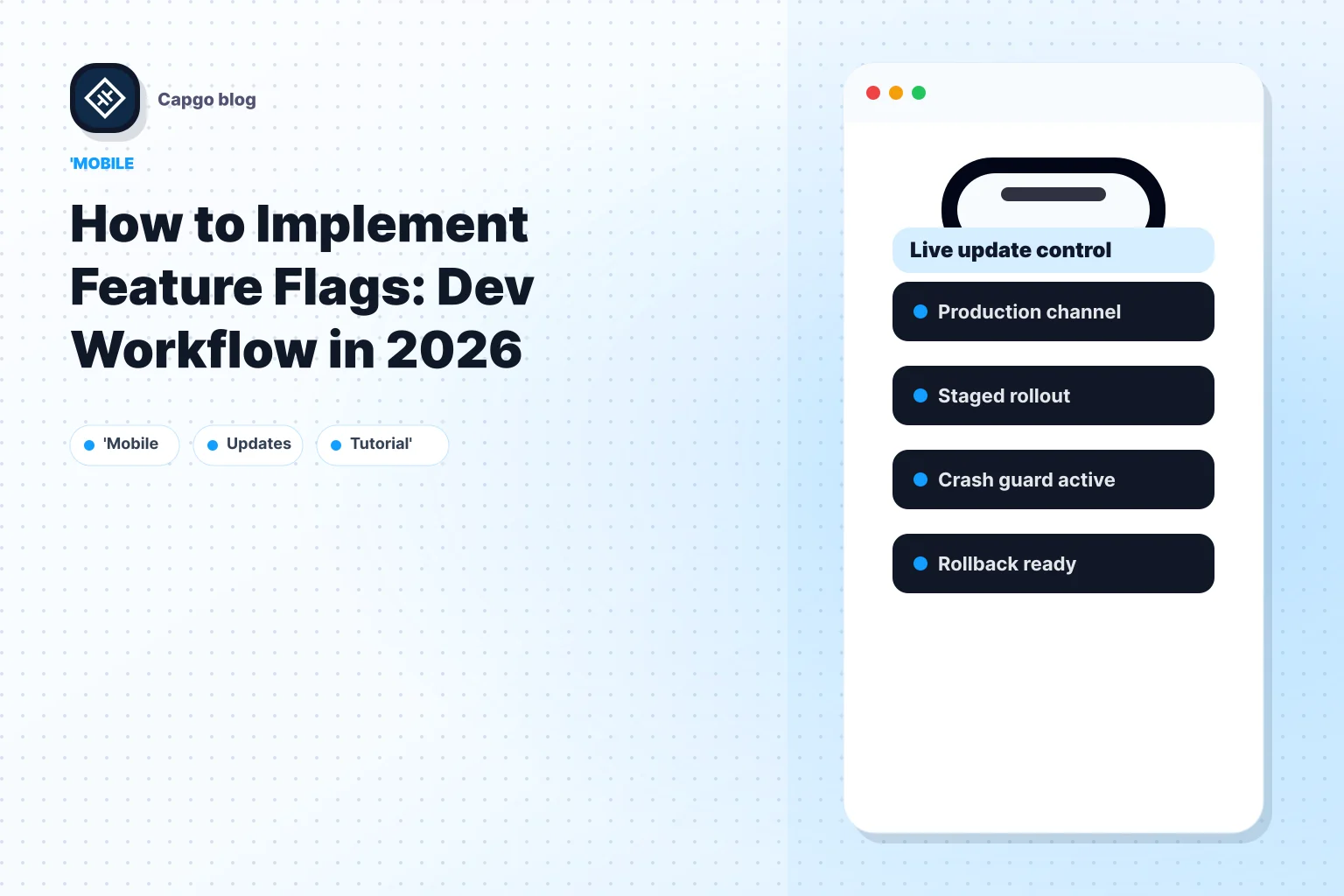
Se il vostro piano di rollback è “sposta la flag in basso”, verificate che il client abbia già un fallback sicuro code. Se non lo ha, associate le flag con aggiornamenti in tempo reale in modo da poter disabilitare l'esposizione e spedire una correzione senza dover aspettare un rilascio del store.
È lì che l'angolo ibrido cambia la decisione di architettura. Le bandiere del lato server rispondono a “chi dovrebbe vedere questo?” I sistemi di aggiornamento in tempo reale come Capgo rispondono a “cosa code dovrebbe quel utente eseguire in questo momento?” Utilizzate entrambe. Rilasciate una funzionalità agli utenti interni con una bandiera, inviate il bundle del client aggiornato solo a quel cohort, poi allargate l'esposizione mentre la telemetria rimane pulita. Quel pattern vi dà un controllo sulla fascia di impatto più stretto rispetto alle bandiere da sole.
Se costruite in-house, mantenete lo scope stretto e esplicito. Definite uno schema di bandiera, centralizzate le regole di valutazione, aggiungete un management API, registrate ogni modifica e stabilite una politica di rimozione prima che la prima bandiera parta. Se acquistate, testate il comportamento del SDK nelle cattive condizioni di rete e attraverso i riavvii dell'app. Se vi auto-hostate, budgetate tempo di ingegneria per gli aggiornamenti, la proprietà di chiamata in caso di emergenza e il lavoro di integrazione del client fin da subito.
Modelli di Implementazione di Base per Applicazioni Cross-Platform
Un'app ibrida fallisce di solito ai confini, non nella definizione della bandiera stessa.
Il modo di fallimento più comune è familiare. Le code web leggono un valore di bandiera a partenza, un plugin Capacitor controlla una copia memorizzata in cache in un momento successivo e una finestra di Electron valuta la stessa bandiera nuovamente con un contesto di utente leggermente diverso. Ora la release è inconsistente tra piattaforme e il rollback diventa una questione di stima.

Inizia semplice, poi centralizza velocemente
Ogni bandiera di funzionalità inizia come un __CAPGO_KEEP_0__ if/else:
if (flags.newCheckout) {
renderNewCheckout();
} else {
renderLegacyCheckout();
}Quello è bene per il primo commit. Stoppa di essere bene una volta che la stessa bandiera viene controllata in cinque posti e ogni layer l'interpreta in modo diverso.
l'articolo di Martin Fowler sui modelli di toggle di feature dà ancora la base di riferimento giusta. Mantieni la logica di valutazione centralizzata, e mantieni le condizionali vicine all'orlo del flusso invece di diffonderle attraverso componenti di basso livello. Negli app cross-platform, i punti di valutazione utili sono di solito:
Configurazione della richiesta del server
- per SSR, __CAPGO_KEEP_0__ formattazione, o consegna della configurazione iniziale for SSR, API shaping, or initial config delivery
- dopo che hai caricato il contesto di identità, dispositivo e ambiente Confine di route o schermo
- dove intere flussi differiscono dallo stato della bandiera Evita di valutare la stessa bandiera all'interno di componenti nidificati, ponti nativi e utilità di aiuto. Quel pattern crea un allontanamento veloce.
Martin Fowler’s
Passa decisioni, non bandiere raw
Una implementazione matura separa i valori delle bandiere dei fornitori dalle decisioni dell'applicazione.
Il tuo provider di bandiere risponde a domande di basso livello come newCheckout=true. La tua app dovrebbe consumare decisioni di alto livello come showNewCheckout, enableDesktopSidebar, o allowBackgroundSync. Quel layer è dove si codificano le regole commerciali, le restrizioni della piattaforma e il comportamento di fallback.
Questa indirezione extra si ripaga velocemente.
Conserva i componenti React puliti. Riduce la dipendenza da un SDK. Inoltre, ti dà un posto per rispondere a una domanda che le squadre ibride affrontano costantemente: questo utente ha sia la bandiera che il code client corretto?
Quel punto ultimo conta per Capacitor e Electron. Un server può capovolgere l'esposizione istantaneamente, ma il client ancora ha bisogno di code che possono renderizzare sicuramente la feature. Combinare l'evaluazione delle bandiere con la consegna di pacchetti mirati è come chiudere quella lacuna. Capgo’s guida a aggiornamenti in tempo reale con segmentazione degli utenti mostra il modello operativo. Valuta chi dovrebbe ricevere la feature, poi consegni l'aggiornamento del client corrispondente a quel cohort senza aspettare una revisione dell'app store.
Un pattern pratico di TypeScript
Ecco un pattern che scalda meglio delle verifiche brute nei componenti.
type UserContext = {
userId?: string;
country?: string;
plan?: 'free' | 'pro' | 'enterprise';
platform: 'web' | 'capacitor' | 'electron';
isInternal?: boolean;
};
type RawFlags = {
newCheckout: boolean;
desktopSidebarRedesign: boolean;
smartSync: boolean;
};
class FeatureFlagService {
constructor(private flags: RawFlags, private user: UserContext) {}
get decisions() {
return {
showNewCheckout: this.flags.newCheckout && this.user.plan !== 'free',
showDesktopSidebar: this.user.platform === 'electron' && this.flags.desktopSidebarRedesign,
enableSmartSync: this.flags.smartSync && this.user.country !== undefined,
};
}
}Esegui una volta vicino all'inizio dell'applicazione:
async function bootstrapApp() {
const user = await getUserContext();
const flags = await fetchFlagsForUser(user);
const featureService = new FeatureFlagService(flags, user);
const decisions = featureService.decisions;
startApp({ user, decisions });
}Poi mantieni la UI stupida:
type AppProps = {
decisions: {
showNewCheckout: boolean;
showDesktopSidebar: boolean;
enableSmartSync: boolean;
};
};
function App({ decisions }: AppProps) {
return (
<>
{decisions.showDesktopSidebar ? <NewSidebar /> : <LegacySidebar />}
{decisions.showNewCheckout ? <CheckoutV2 /> : <CheckoutV1 />}
</>
);
}Quella struttura ti dà coerenza su più schermate, test più semplici e un percorso di rimozione più pulito una volta completata la distribuzione.
Aggiungi la piattaforma e la prontezza dell'aggiornamento alla layer di decisione
Gli app ibride hanno bisogno di un ulteriore controllo che i tutorial di flag generici spesso trascurano. Una funzionalità non dovrebbe attivarsi solo perché il flag remoto dice sì. Dovrebbe attivarsi solo se il client installato o aggiornato in tempo reale può supportarlo.
Quello significa che la tua layer di decisione spesso ha bisogno di input oltre le flag brute:
- versione corrente dell'app
- versione corrente del pacchetto live
- piattaforma
- stato offline
- disponibilità della capacità nativa
A un oggetto di decisione si può esprimere direttamente:
type RuntimeContext = {
appVersion: string;
bundleVersion?: string;
isOffline: boolean;
hasNativeBiometrics: boolean;
};
function buildDecisions(flags: RawFlags, user: UserContext, runtime: RuntimeContext) {
return {
showNewCheckout:
flags.newCheckout &&
user.plan !== 'free' &&
runtime.bundleVersion === 'checkout-v2',
enableSmartSync:
flags.smartSync &&
!runtime.isOffline,
enableBiometricUnlock:
flags.smartSync &&
runtime.hasNativeBiometrics &&
user.platform === 'capacitor',
};
}Si tratta del compromesso pratico. Il livello di decisione diventa più complesso, ma l'applicazione diventa più sicura da utilizzare. Le squadre che saltano questo passaggio solitamente scoprono il divario durante il rollback, quando la bandiera è spenta ma il code incompatibile è già attivo sui dispositivi, o la bandiera è accesa per gli utenti che non hanno mai ricevuto il pacchetto richiesto.
Usare la bucketizzazione deterministica per qualsiasi logica di rollout
La logica di rollout percentuale appartiene a un posto solo. Non assegnare gli utenti in modo casuale a ogni render o avvio dell'app. Usare un identificatore stabile e una hashing deterministica affinché lo stesso utente rimanga nello stesso bucket.
function isInRollout(featureName: string, userId: string, rolloutGate: number): boolean {
const bucket = stableHash(`${featureName}:${userId}`) % 100;
return bucket < rolloutGate;
}La funzione di hash esatta è meno importante del comportamento. Lo stesso input dovrebbe sempre atterrare nello stesso bucket. Se si consegnano anche aggiornamenti in tempo reale, mantenere l'input di bucketizzazione allineato con le regole di pubblico utilizzate per spedire i pacchetti. Altrimenti si può esporre una bandiera di feature agli utenti che non sono mai stati inviati il supporto code.
Una regola finale aiuta a evitare una grande quantità di pulizia in seguito. Tenere le verifiche delle bandiere fuori dai componenti foglia riciclabili a meno che il componente esista solo per quell'esperimento. Mettere il branching al confine di route, schermo o servizio e lasciare il resto del tree render un solo percorso scelto.
Rollout Strategici e Targeting di Pubblico
Un piano di rilascio viene testato per la prima volta quando il comportamento della produzione è diverso per un pezzo di utenti rispetto ad un altro. Un flusso di checkout funziona su desktop Electron, fallisce su vecchie build Android WebView, e il supporto deve sapere chi è esposto in questo momento. Questo è il punto in cui una flag booleana non è più sufficiente.

La storia di rilascio di un nuovo flusso di checkout
Dire che si sta spedito new-checkout in un'app Capacitor con una build desktop Electron. Il cambiamento di interfaccia vive dietro una flag server-side, ma una parte della logica di supporto viene inviata come client code. Se questi due sistemi non sono allineati, gli utenti possono ottenere la flag prima di avere il pacchetto, o ottenere il pacchetto prima di vedere la feature.
Inizia con conti di personale e dispositivi QA. Poi muovi gli utenti beta opt-in su una piattaforma, come solo Electron, mentre i dispositivi mobili rimangono sulla vecchia strada. Dopo di che, espandi per cohort e percentuale mentre osservi le tassi di errore, le fallite di pagamento e i ticket di supporto. Mantieni il vecchio checkout raggiungibile fino a quando il rollout non ha superato il traffico reale su ogni piattaforma che supporti.
Una politica pratica per quella feature assomiglia a questo:
- Cohorte interna per prima: sviluppatori, QA, supporto e conti demo
- Utenti beta per piattaforma: utenti di accesso anticipato, ma solo sulle versioni dell'app e sui runtime che si fidano
- Produzione in passaggi: Aumenta l'esposizione in piccoli incrementi e frena su qualsiasi regressione
- Fallback mantenuto in vita: La vecchia path rimane chiamabile fino a quando la nuova path non è stabile in produzione
Per le app ibride, la politica di rollout richiede anche una politica di consegna. Aggiornamento live per la segmentazione degli utenti per Capacitor app Mostra come spedire il bundle client matching alla stessa cohort del tuo sistema di flag. Quella connessione conta perché il controllo delle rilasci è debole se il flag e il code spedito seguono regole di pubblico diverse.
Regole di targeting che mantengono la produzione
Un buon targeting utilizza attributi che puoi spiegare e riprodurre durante un incidente. Piattaforma, versione dell'app, regione, livello di account, stato dell'utente interno e iscrizione beta sono comuni perché sono spesso disponibili al momento dell'evaluazione e stabili abbastanza per l'audit e il supporto.
Un cattivo targeting dipende da valori che si presentano in ritardo o cambiano spesso. Stato di sessione locale, campi di profilo sincronizzati parzialmente o proprietà client-only creano disallineamenti difficili da debug tra ciò che il server intendeva e ciò che l'app ha reso.
Usa regole che il tuo team può leggere senza aprire tre dashboard. internal, beta_mobile, e enterprise_desktop_v2 Sono più facili da gestire degli ID di segmento anonimi. Il supporto dovrebbe essere in grado di rispondere a una domanda velocemente: perché questo utente ha ricevuto questa funzionalità?
One più trade-off da rendere esplicito è che la gestione di targeting da parte del server mantiene la politica centralizzata, ma le applicazioni ibride ancora hanno bisogno di abbastanza contesto del client per applicare fallback locali sicuri quando la rete è lenta o non disponibile.
Il meccanismo di interruzione è parte del design
Un meccanismo di interruzione è parte del design di rilascio fin dal primo giorno. Non è lavoro di pulizia per un momento successivo.
Per le funzionalità di fronte ai clienti, mantieni il percorso precedente attivo fino a quando il nuovo non ha superato traffico di produzione reale attraverso i tuoi maggiori cohort. Se i fallimenti di checkout aumentano per una regione o un runtime, dovresti essere in grado di disabilitare la funzionalità per quel pubblico immediatamente senza attendere una revisione dell'app store.
Gli applicazioni ibride aggiungono un altro strato. Una bandiera di server può nascondere un percorso rotto, ma non può riparare code già installato sui dispositivi. I sistemi di aggiornamento in tempo reale come Capgo chiudono quel divario. Puoi disabilitare la funzionalità, quindi invia un bundle corretto al cohort interessato al posto di attendere il prossimo ciclo di rilascio completo.
Quella combinazione è ciò che rende le roll-out operative al posto di teoriche. Le bandiere controllano l'esposizione. La targeting limita il raggio d'azione. Gli aggiornamenti in tempo reale riparano il client velocemente quando il comportamento di runtime e i code spediti si allontanano.
Testare l'osservabilità e l'igiene delle bandiere
A le feature flag aggiunge code percorsi, problemi di timing e stato che ora devi ragionare in produzione. Se non testi e osservi lo stato direttamente, il flag sposta il rischio invece di ridurlo.
Testa entrambe le branch per proposito
Tratta ogni flag come due rilasci che vivono nello stesso codice. Il vecchio percorso ancora ha bisogno di protezione mentre il nuovo percorso si avvia e il nuovo percorso ha bisogno di una prova che comporti correttamente sotto condizioni di app reali.
A livello di unità, inietta la decisione del flag in modo che i test rimangano deterministici. A livello di integrazione e fine-a-cancello, fornisce a QA e CI un sovraccarico controllato. Non contare sulle regole di targeting live durante un run di test. Quelle regole cambiano, le cache scadono e improvvisamente un test flaccido ti sta raccontando più sulla programmazione del tempo di rollout che sul comportamento del prodotto.
Per le app ibride, testa i momenti in cui lo stato del flag può deviare da stato dell'app:
- Percezioni abilitate e disabilitate: mantieni la copertura su entrambi fino a quando il flag non viene eliminato.
- Cohorti di confine: verifica le regole di dipendente, beta, pagato, regionale e utente anonimo separatamente.
- Lancio, ripresa e flussi di ricarica: molte Capacitor e app Electron rievalueranno lo stato in quei punti.
- Comportamento di fallback offline: conferma che il client utilizza l'ultima decisione conosciuta o un valore di default sicuro quando la rete non è disponibile.
- Compatibilità del pacchetto: se un flag esporre code consegnato attraverso un aggiornamento in tempo reale, verificare che l'app non abbia abilitato l'interfaccia utente che il bundle corrente non può supportare.
Quel punto è facile da dimenticare. Un server può decidere che un utente debba vedere una funzione, ma il client deve comunque confermare che il bundle installato e il runtime nativo possono eseguirla in modo sicuro.
Osserva il flag, non solo la funzione
L'strumentazione dovrebbe consentirti di rispondere a tre domande velocemente. Chi ha visto il flag? Quale code percorso è stato eseguito? Quale versione del bundle era attiva quando è stato eseguito?
I team spesso configurano il flag e si fermano lì. Poi un picco di errori compare in produzione e nessuno può capire se il problema sia venuto dal flagato code, da un segmento di pubblico o da un bundle del client obsoleto. La soluzione è semplice. Aggiungi lo stato del flag valutato agli eventi di analisi, ai log, alle tracce e ai rapporti di errore. Non registrare solo feature=new_checkoutRegistra la decisione effettiva, la regola o il cohort che l'ha prodotta, e la versione del client che l'ha eseguita.
Una semplice forma di evento è di solito sufficiente:
{
"event": "checkout_started",
"flag_new_checkout": true,
"flag_rule": "beta_users_us",
"app_version": "5.4.1",
"bundle_version": "2026.06.13-2",
"platform": "capacitor-ios"
}Quella struttura rende il debug in produzione molto più veloce. Puoi separare una regola di distribuzione difettosa da un bundle difettoso, e puoi vedere se un platform sta fallendo mentre un altro è sano.
Per le applicazioni ibride metriche di aggiornamento in tempo reale per le app Capacitor aiutare a chiudere la breccia tra il controllo della versione e la prova di esecuzione. Quando combiniamo i dati di esposizione delle funzionalità con i dati di adozione dei pacchetti, possiamo capire se una regressione è venuta dalla decisione del flag, dallo JavaScript spedito o dall'interazione tra i due.
Un flag senza osservabilità è una complessità nascosta con un pulsante di dashboard attaccato.
La pulizia fa parte dell'implementazione
I debiti dei flag si trasformano velocemente in debiti di code.
I flag peggiori sono quelli che sono riusciti e che nessuno ha eliminato. Loro tengono vive le branch morte, confondono gli ingegneri di onboarding e espandono la matrice di test molto dopo che la decisione di rollout è stata presa. Negli app ibride, anche rendono più difficile l'aggiornamento in tempo reale perché si sta portando la logica di compatibilità per stati che non hanno più importanza.
Stabilisci le regole di igiene quando il flag viene creato:
- Assegna un proprietario.
- Registra la condizione di rimozione.
- Apre la task di pulizia immediatamente.
- Cancella i code morti non appena la rollout è completa.
- Archivia o rimuovi l'ingresso del flag in modo che il supporto e l'ingegneria non lo trattino come attivo.
Consiglio anche una regola pratica per i team che inviano attraverso flag server-side più aggiornamenti in tempo reale. Se un flag esiste solo per proteggere una breve migrazione tra vecchi e nuovi pacchetti client, dategli una breve data di scadenza e revisionatelo con il proprietario di rilascio, non come pulizia generale del backlog. I flag temporanei si moltiplicano velocemente in Capacitor e app Electron, soprattutto quando si stanno patching il comportamento di produzione senza aspettare un rilascio completo della store.
Automazione e potenziamento delle bandiere con CI/CD e aggiornamenti in tempo reale
Il flusso di lavoro manuale delle bandiere non scalano bene. Falliscono anche al momento peggiore, solitamente durante un hotfix.
Una configurazione matura lega le bandiere allo stesso processo di consegna che costruisce, testa e invia l'applicazione.

Includi la creazione delle bandiere nel processo di consegna
Quando una branca di feature si unisce, il tuo pipeline dovrebbe già sapere abbastanza per creare o validare la bandiera che la proteggerà. Ciò non significa che ogni commit debba avere una nuova impostazione. Significa che il controllo delle rilasci dovrebbe essere sistematico, non conoscenza tribale detenuta da chi ha unito per ultimo.
Le automazioni utili includono:
- Verifica dello schema delle bandiere: verifica i nomi, i proprietari e i piani di scadenza prima dell'unione.
- Impostazioni predefinite dell'ambiente: Le nuove feature pericolose dovrebbero partire disabilitate in produzione a meno che non siano state esplicitamente approvate.
- Note di rilascio con stato delle bandiere: supporto e QA devono sapere quali funzionalità sono bloccate nella build.
- Ricordi di pulizia: le vecchie bandiere dovrebbero emergere nel workflow di ingegneria prima di diventare un disordine permanente.
Se stai integrando questo nel pipeline di distribuzione mobile e ibrida, configurare CI/CD per le app Capacitor è il lato operativo dello stesso problema.
Dove gli aggiornamenti in tempo reale cambiano l'equazione
Gli app ibride hanno bisogno di un diverso libro di strategia rispetto agli app web puri.
Una bandiera server-side decide chi dovrebbe vedere una funzionalità. Ma a volte il code dietro quella funzionalità ha bisogno di cambiare dopo che il binario dell'app è già nelle mani degli utenti. In Capacitor e Electron, ciò crea una lacuna di rilascio. La bandiera può nascondere o esporre un percorso, ma non può ricompilare il bundle del client da sola.
È per questo che i sistemi di aggiornamento in tempo reale si abbinano così bene con le bandiere di funzionalità. La bandiera controlla chi dovrebbe vedere la funzionalità. Il canale di aggiornamento controlla quale cliente code ricevono. Ad esempio, un team potrebbe utilizzare LaunchDarkly o Unleash per la targeting in tempo di esecuzione e utilizzare Capgo per consegnare JavaScript, CSS, copia, configurazione e asset aggiornati a specifiche canali in un'applicazione Capacitor o Electron senza dover attendere la revisione della store.
Quella combinazione è particolarmente efficace per il rollout mirato in ambienti ibridi:
- Targeting server-side: scegliere l'utenza in tempo di esecuzione.
- Distribuzione client-side: inviare il bundle esatto che supporta la feature.
- Ripristino operativo: disabilitare la feature, spedire un bundle fissato, o entrambi.
- Consistenza della piattaforma: mantenere la logica delle rilasci web, desktop e mobile allineata anche quando i meccanismi di consegna differiscono.
Questa guida passo passo offre una visione concreta di come le squadre gestiscano quel workflow nella pratica:
Se sei serio sul modo in cui implementare le bandiere di feature in un stack ibrido, pensa in layer. Un layer decide l'esposizione. Un altro consegna code. Un terzo osserva cosa è successo. Quando quei layer sono separati ma coordinati, le rilasci smettono di sentire come scommesse irreversibili e iniziano a comportarsi come operazioni controllate.
Capgo si adatta a quel secondo layer per le squadre che distribuiscono applicazioni con CapacitorJS e Electron. Fornisce aggiornamenti in tempo reale, targeting basato sui canali, controlli di rollback, osservabilità e integrazione CI/CD per la consegna del pacchetto web, il che lo rende un complemento pratico a un sistema di bandiere di feature server-side quando la strategia di rilascio dipende sia dal controllo runtime che da riparazioni client-side veloci.


