Normalmente, un problema de DevEx se nota en medio de una entrega. El CI está bloqueado, solo funciona la firma en un portátil, una actualización de emergencia está bloqueada por la revisión de la tienda de aplicaciones, y el soporte no puede determinar si los usuarios están golpeando una versión antigua, un lanzamiento malo o un error de tiempo de ejecución. Los métricas de sprint raramente lo capturan tan temprano. El equipo lo siente primero.
“Las herramientas de experiencia del desarrollador” ahora cubren un conjunto amplio de productos en lugar de una etiqueta difusa. Los equipos evalúan DevEx con señales del sistema y retroalimentación directa del desarrollador, y los proveedores se posicionan cada vez más en torno a la telemetría de flujo de trabajo, encuestas y análisis de productividad relacionado con la inteligencia artificial extraído de Git, Jira y sistemas CI/CD. En la práctica, la pregunta útil es más simple: ¿cuáles herramientas eliminan la fricción de construir, enviar, depurar, liberar y volver a enviar software?
That se vuelve más difícil para Capacitor y los equipos de Electron. Los code web se envían dentro de un wrapper nativo, por lo que la superficie de operación se extiende a través de la infraestructura de compilación, la code de firmas, la distribución de beta, las actualizaciones en vivo, la visibilidad de errores y el control de lanzamiento. Las transferencias de productos, diseño y ingeniería también se rompen más rápido cuando la propiedad de la liberación es vaga. Si su equipo todavía está ajustando ese proceso, esta guía sobre las mejores prácticas de transferencia de desarrolladores es digna de leer junto con las opciones de herramientas en este artículo. Prácticas recomendadas de transferencia de desarrolladores es digna de leer junto con las opciones de herramientas en este artículo.
La estructura aquí sigue el ciclo de vida, no una clasificación genérica. Las herramientas de compilación y CI pertenecen a un mismo contenedor. La entrega y la distribución de actualizaciones pertenecen a otro. La observabilidad y el control de características resuelven un tipo diferente de problemas. Esa forma de presentar las cosas hace que las compensaciones sean más claras, y conduce a la parte que muchos equipos necesitan: pilas de DX opinativas para desarrolladores en solitario, equipos en crecimiento y empresas reguladas.
Índice
- 1. Capgo
- 2. Capawesome Cloud
- 3. Bitrise
- 4. Codemagic
- 5. VoltBuilder
- 6. Expo Application Services EAS Build plus EAS Update
- 7. fastlane
- 8. Firebase App Distribution
- 9. Sentry
- 10. LaunchDarkly
- Herramientas de experiencia del desarrollador: Comparación de las 10 características más destacadas
- Construyendo tu pila de DX
1. Capgo

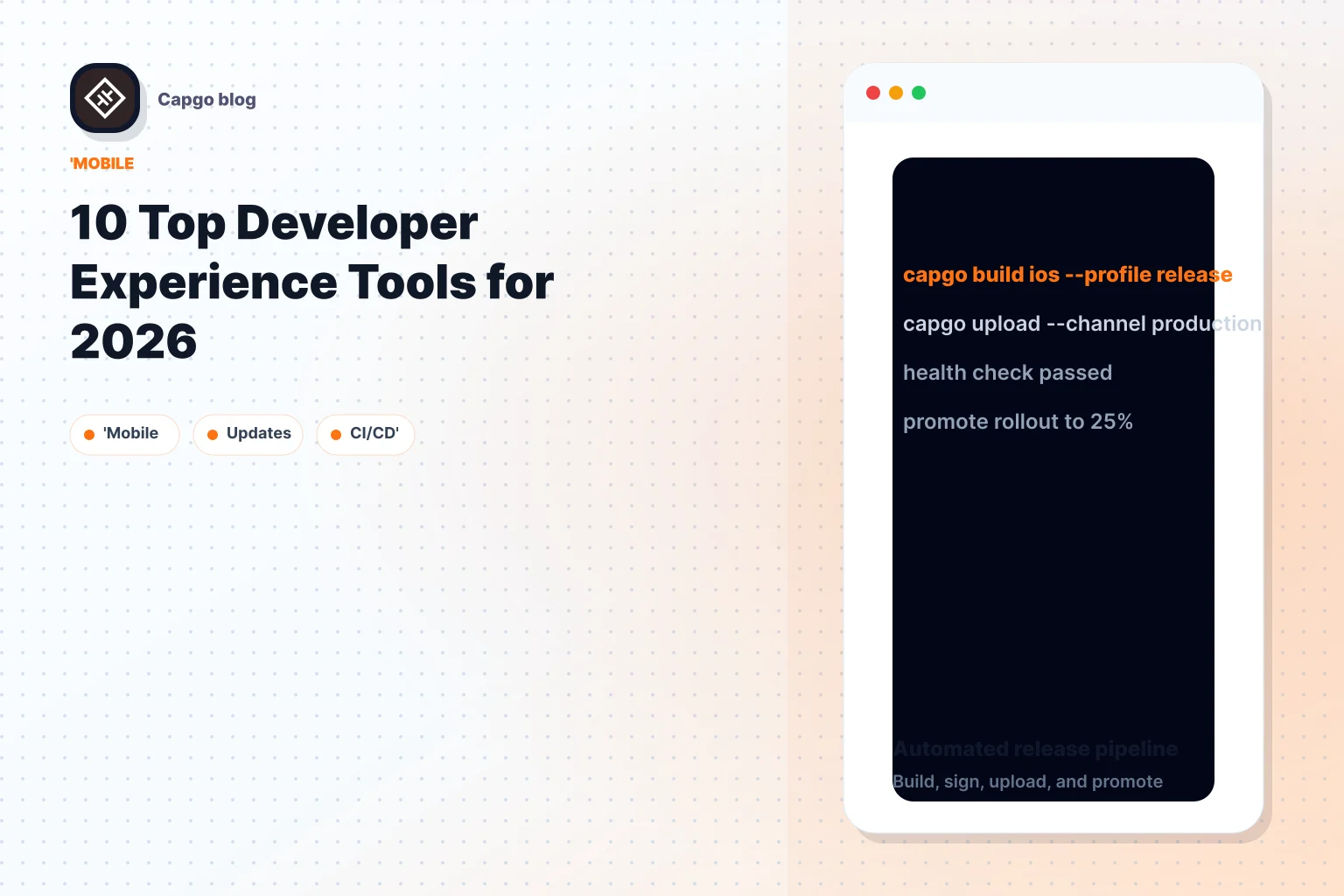
Un error de producción cae el viernes por la tarde. La solución vive enteramente en la capa web, pero la aplicación sigue detrás de la revisión de la tienda. Para los equipos que envían con Capacitor o Electron, Capgo acorta ese ciclo entregando actualizaciones de JavaScript firmado, CSS, configuración, copia y recursos sin tener que esperar a una liberación nativa completa.
That coloca a la actualización en vivo en la parte de la pila de DX, no en el contenedor CI/CD o de observabilidad.
Capgo combina un plugin de actualizador de código abierto con un servicio de entrega hospedado. Los equipos instalan el actualizador una vez, publican paquetes firmados a través de CLI o API, y permiten a los clientes descargar actualizaciones en la próxima ejecución. En la práctica, las partes útiles son los controles operativos alrededor de ese flujo: canales, objetivo de lanzamiento, manejo de retroceso, historia de versiones y cronogramas por dispositivo que muestran exactamente qué sucedió durante un intento de actualización.
¿Por qué Capgo ocupa el lugar destacado?
Muchas herramientas de actualización en vivo se detienen en la entrega de paquetes. Capgo va más allá en las operaciones de lanzamiento. Los registros por dispositivo exponen comprobaciones, descargas, instalaciones y señales de retroceso, lo que da a soporte y a ingeniería la misma vista durante un incidente.
Importa porque los equipos están enviando más rápido, a menudo con más code generado y más volumen de lanzamiento de lo que tenían un año atrás. La velocidad ayuda hasta que una solución casi correcta llega a producción. En ese punto, la herramienta de DX mejor es la que hace que el retroceso y el control del radio de explosión sean aburridos.
Regla práctica: Si la mayoría del riesgo de lanzamiento se encuentra en la capa web, reduce el tiempo desde “encontramos el error” hasta “la parche está en dispositivos.”
The historia de automatización también es sólida. El CLI, API, interfaces de TypeScript tipados, y las integraciones de CI se ajustan a los flujos de trabajo de liberación móvil normales sin mucho pegamento code. Las actualizaciones diferenciales mantienen los payloads más pequeños al enviar solo archivos modificados, lo que es un beneficio real para los usuarios en redes más lentas y para los equipos que empujan parches frecuentes.
Dónde Capgo se ajusta y dónde no
Capgo se ajusta a los equipos que ya tienen pipelines de compilación nativa y necesitan una forma más segura de enviar actualizaciones web después de que el binario esté en manos de los usuarios. Los canales de beta, las implementaciones de etapas, los flujos de clientes específicos, y las señales de adopción y fracaso visibles lo hacen útil para el trabajo diario de liberación, no solo para reparaciones de emergencia.
El intercambio es claro. Capgo no reemplaza la herramienta de compilación nativa y la presentación de tiendas. Los cambios en la code, las licencias, los SDK, o los metadatos de la tienda todavía pasan por el proceso habitual de iOS y Android.
Puntos prácticos destacados:
- Mejor ajuste: Los equipos de CapacitorJS y Electron que necesitan arreglos web rápidos y claridad en la visibilidad de la liberación.
- Controles de seguridad fuertes: Paquetes firmados, protección de rollback, historia de versiones, y reglas de canal reducen el riesgo de liberación.
- Útil para el soporte: Los horarios de dispositivo por dispositivo ayudan a soporte y a ingeniería a depurar el comportamiento de liberación desde la misma evidencia.
- Límite principal: Los cambios nativos todavía requieren el camino estándar de la Tienda de App y la Tienda de Juegos.
Para equipos que utilizan herramientas de mapeo por función de ciclo de vida, Capgo pertenece a la parte post-construcción, post-lanzamiento de la pila. Ayuda después de que CI ha terminado y después de que la aplicación ya está en producción, lo que es exactamente donde se muestra la mayoría de los dolores de parto de entrega móvil.
2. Capawesome Cloud

Capawesome Cloud Es el tipo de plataforma que te recomendaría cuando un equipo ya ha elegido Capacitor y quiere menos partes móviles. Trae construcciones nativas, automatización de publicación en tiendas y actualizaciones en vivo a una configuración de Capacitor-primero.
Ese enfoque es su mayor ventaja. Los proveedores de CI generales pueden manejar Capacitor, pero a menudo necesitan más pegamento, más scripts personalizados y más mantenimiento de la línea de producción. Capawesome Cloud comienza desde la suposición de que Capacitor es el centro del flujo de trabajo, lo que a menudo significa menos fricción de configuración para equipos de Ionic y Capacitor.
Mejor para equipos de Capacitor que quieren una plataforma opinada
La atracción aquí no es la amplitud. Es la alineación. Si estás migrando desde herramientas de entrega de aplicaciones móviles más antiguas o reemplazando un flujo de trabajo de estilo Appflow, Capawesome Cloud te da una ruta moderna y propósito construida con actualizaciones en vivo, canales, code de firma y construcciones en la nube en iOS y Android.
Su posicionamiento a precio fijo también atraerá a los equipos que desprecian la incertidumbre de la facturación por minuto. El cálculo de costos para la CI móvil puede volverse fastidioso una vez que los edificios en paralelo, las reintentadas y las ramas de lanzamiento comiencen a multiplicarse. Un modelo de precios más simple puede mejorar la experiencia del desarrollador eliminando la fricción de aprobación alrededor del uso de la canalización.
Capawesome Cloud es la opción más adecuada cuando su equipo quiere la estandarización más que la máxima flexibilidad.
El contrapeso es que es más estrecho que una plataforma de CI/CD amplia. Si su pila abarca servicios de backend, aplicaciones web y lanzamientos móviles bajo una capa de automatización gigante, puede preferir todavía un proveedor de canalización más general. Pero para una tienda Capacitor-pesada, lo estrecho a menudo es bueno. Lo estrecho significa menos abstracciones luchando contra el marco.
Una lectura rápida sobre la compatibilidad:
- Buena elección: Los equipos que quieren construir, publicar y actualizar en vivo de manera estrechamente relacionada con Capacitor.
- Beneficio operativo agradable: Menos pegamento personalizado code que los ajustes de CI generales.
- Beneficio presupuestario: La facturación a precio fijo es más fácil de explicar internamente.
- Desventaja principal: Si Capacitor no es central en la entrega de la aplicación, la especialización importa menos.
3. Bitrise

Bitrise Ha sido un nombre familiar en CI/CD móvil por una buena razón. Entiende las partes feas de la entrega móvil: ejecutores macOS, code firma, entornos de compilación inestables y el hecho de que las flujos de liberación rara vez permanecen simples a largo plazo.
Esta es una mejor opción para equipos que necesitan flujos de trabajo configurables y esperan que su automatización crezca más compleja con el tiempo. Ejecutores de macOS y Linux hospedados, un gran mercado de pasos y opciones de caché de compilación dan a los equipos experimentados espacio para ajustar la velocidad y la estructura en lugar de aceptar un modelo rigido.
Mejor para CI móvil con espacio para personalizar
Bitrise es más fuerte cuando su proceso de compilación no es solo “ejecutar una orden y subir.” Muchos equipos de productos necesitan flujos de trabajo para la validación de solicitudes de extracción, distribución nocturna, liberaciones basadas en ramas, generación de capturas de pantalla, presentación en tiendas y notificaciones en varios aplicativos. Bitrise maneja bien ese tipo de trabajo.
La advertencia es la planificación de costos. Una vez que trabaja con opciones de máquina, minutos de compilación, cachés y flujos de trabajo paralelos, la plataforma le da levers útiles pero también más variables de facturación. Eso no es necesariamente malo. Solo significa que finanzas y ingeniería necesitan una visión más clara de la consumo.
Las herramientas de experiencia del desarrollador solo ayudan si eliminan la tedencia. Una reciente ronda de discusión sobre DORA y la investigación de Google Cloud hace bien el punto: los equipos ya pasan un tiempo sustancial en la deuda técnica, las interrupciones y la coordinación, por lo que el objetivo es reducir la fricción en lugar de agregar sobrecarga de medición (Jellyfish al elegir herramientas de experiencia del desarrollador que reducen la tedencia)
- Bitrise puede eliminar completamente la tedencia, pero solo si alguien se hace cargo de la higiene de la canalización. Lo que funciona bien:
- CI/CD móvil con muchos puntos de integración y flexibilidad de flujo de trabajo. Lo que puede ir mal:
- Una canalización personalizada crece más rápido que su documentación. Quién debe comprarlo:
Equipos con propiedad de liberación dedicada o suficiente madurez para mantener estándares de CI compartidos.

Codemagic Codemagic se adapta bien a esa parte del ciclo de vida.
Es una herramienta de CI/CD primero, con un claro apoyo para Flutter, React Native y rutas de trabajo para Capacitor equipos. En comparación con sistemas de flujo de trabajo más pesados, Codemagic suele pedir menos decisiones de plataforma de antemano. Eso lo hace más fácil de entregar a un pequeño equipo de producto que necesita construcciones reproducibles, code firmas de código, automatización de pruebas y entrega a tiendas sin convertir a un desarrollador en el administrador de CI a tiempo parcial.
Ideal para equipos que buscan flexibilidad en el precio
El modelo de precios es parte de la atracción. Codemagic ofrece capacidad de construcción basada en uso en macOS, Linux y Windows, y también tiene planes anuales fijos para equipos que necesitan un presupuesto más estable. Eso es un trueque práctico, no una característica llamativa. Los equipos en etapa inicial pueden pagar por el uso real, mientras que los equipos más grandes pueden reducir las sorpresas mensuales que a menudo aparecen una vez que el volumen de lanzamiento aumenta.
Su soporte de CodePush alojado también es útil para equipos de React Native. Mantener la automatización de construcción y la entrega OTA bajo un mismo proveedor puede simplificar la propiedad, especialmente si el equipo todavía está ensamblando su paquete de DX más amplio a través de CI/CD, actualizaciones en vivo, distribución y observabilidad.
The limitación es alcance. Codemagic cubre bien la automatización de compilación y lanzamiento, pero no reemplazará todas las necesidades de actualización en vivo o de lanzamiento en cada pila móvil. Si el equipo necesita un gobierno de actualización más avanzado, un control de lanzamiento en etapas o un comportamiento OTA específico de pila fuera de React Native, pair Codemagic con otra herramienta puede ser más sensato que obligarla a cubrir tareas para las que no fue diseñada.
Me gusta Codemagic más para equipos que quieren un modelo operativo más limpio que una configuración de CI personalizada completa, pero todavía necesitan algo más que una utilidad básica de compilación alojada.
- Mejor ajuste: Equipos que quieren opciones de CI de pago por uso o anuales fijas.
- Fuerte especialmente: Tiendas de Flutter y equipos de React Native que quieren OTA gestionado junto con la automatización de compilación.
- Ten cuidado con: Herramientas adicionales si su proceso de lanzamiento necesita un control de lanzamiento más profundo o una cobertura de actualización en vivo más amplia.
5. VoltBuilder

No todos los equipos necesitan una plataforma de CI/CD completa. A veces el bloqueador es mucho más simple: nadie quiere mantener un SDK de configuración local y nadie en el equipo tiene un Mac para los builds de iOS. Eso es donde VoltBuilder obtiene su lugar.
VoltBuilder is closer to a hosted build utility than a broad automation system. Upload the app package, handle signing, get store-ready binaries back. For small agencies, legacy Cordova shops, and straightforward Capacitor projects, that simplicity is the point.
Para pequeñas agencias, tiendas de Cordova legadas y proyectos __CAPGO_KEEP_0__ sencillos, esa simplicidad es el punto.
Mejor para el camino más rápido a binarios firmados
Me gusta VoltBuilder cuando la botella de cuello del equipo es el sobrecoste de la infraestructura en lugar de la sofisticación de la canalización. Si tu proceso de liberación sigue siendo principalmente manual y la aplicación no justifica una plataforma móvil interna completa, un servicio estrecho puede mejorar la experiencia del usuario más que uno poderoso.
El lado negativo es obvio. No reemplazará una capa de automatización madura. No obtendrás el mismo tipo de orquestación de flujo de trabajo, modelado de entorno o profundidad de canalización de liberación que esperarías de un proveedor CI más amplio.
- Eso no lo hace menos. Lo hace enfocado. Uso fuerte:
- Pequeños equipos que necesitan compilaciones hospedadas de iOS y Android con configuración mínima. Dato útil:
- No requiere Mac para la ejecución de compilación de iOS. Límite:
6. Servicios de Aplicación de Expo EAS Build más EAS Update

Un colapso común de React Native aparece justo después de que una característica esté lista. El code está hecho, pero obtener una compilación de prueba, enviar una corrección y mantener las liberaciones de tienda bajo control todavía requiere demasiados intercambios de mano. Para los equipos que ya están construyendo alrededor de Expo, Servicios de Aplicación de Expo elimina una gran cantidad de fricción en la etapa de liberación.
EAS Build cubre las compilaciones en la nube y la presentación de la aplicación. EAS Update maneja la entrega en vivo para JavaScript y activos. Juntos, forman una capa de liberación enfocada para la parte de la vida cíclica del ciclo de vida, por lo que esta herramienta pertenece a la categoría de CI/CD y actualizaciones en vivo de una pila de DX en lugar de ser una plataforma móvil genérica.
La atracción es directa. Expo ya ha tomado una serie de decisiones de flujo de trabajo para usted, y EAS extiende esas decisiones a la compilación y la entrega. Eso suele significar menos scripts personalizados, menos configuración de CI y menos lógica de liberación distribuida entre proveedores separados.
Lo recomiendo principalmente para equipos de Expo que quieren un servicio que maneje la salida de compilación y las actualizaciones posteriores a la liberación sin tener que unir herramientas adicionales. Los documentos son maduros, los valores por defecto son sensatos y el proceso de incorporación tiende a ser más rápido porque el ecosistema comparte el mismo modelo mental.
The trade-off es la compatibilidad con la plataforma. Los equipos que utilizan React Native sin envolturas aún pueden obtener valor de EAS, pero la conveniencia disminuye a medida que aumentan la personalización nativa, las pipelines personalizados o los controles de lanzamiento específicos de la organización. En ese punto, la decisión es menos sobre si EAS funciona y más sobre si sus opiniones aún coinciden con la forma en que su equipo envía software.
El costo también necesita atención. Los créditos de construcción, los límites de actualizaciones MAU y la banda ancha pueden permanecer razonables para equipos pequeños, luego se convierte en una preocupación de planificación una vez que el volumen de lanzamientos aumenta.
- Gran ajuste: Los equipos de Expo que desean construir en la nube y realizar actualizaciones OTA en un flujo de trabajo.
- Dónde ayuda más a la DX: La consistencia en la etapa de lanzamiento, especialmente para equipos que envían actualizaciones de JavaScript frecuentes.
- Limitación: Cuanto más se aleje su aplicación y proceso de las convenciones de Expo, más decisiones de configuración regresan a su equipo.
7. fastlane

fastlane Se encuentra en la parte de automatización de lanzamientos de una pila de DX. Espero verlo en equipos que desean que su proceso de envío de móviles esté definido en code en lugar de estar enterrado en listas de verificación, capturas de pantalla y la memoria de alguien de App Store Connect.
Gana su lugar automatizando los pasos repetitivos alrededor de la firma, capturas de pantalla, metadatos, distribución beta y presentación en tiendas. Ese trabajo es tedioso, fácil de hacer mal y costoso de interrumpir. Un buen Fastfile Convierte esas tareas en un flujo de trabajo revisado que el equipo puede ejecutar de la misma manera cada vez.
Mejor para equipos que quieren automatizar la liberación que pueden controlar
La ventaja práctica es el control. fastlane funciona en casi cualquier configuración CI, incluyendo GitHub Acciones, GitLab CI, Jenkins, Bitrise y Codemagic, por lo que se adapta a la pipeline que ya tienes en lugar de forzar un cambio de plataforma. Para equipos que tratan el ingeniería de liberación como parte del código, esa portabilidad importa.
El contrapeso es la mantenibilidad. fastlane te da mucha libertad, y las rutas mal estructuradas pueden convertirse en leyenda de la liberación con una sintaxis mejor. La gestión de secretos, las credenciales de firma y el diseño de la ruta todavía requieren disciplina de ingeniería. Si nadie revisa la automatización code con cuidado, el flujo de liberación se desvía como cualquier otra parte del sistema.
Normalmente recomiendo fastlane para equipos que han superado los pasos de liberación manuales pero no quieren entregar todo el proceso a un servicio hospedado. Es especialmente útil en estacks mixtos donde CI, pruebas, compilación y distribución ya viven en varias herramientas.
“Automatiza los pasos de la tienda primero. Rompen la concentración más que el paso de compilación.”
Como se mencionó anteriormente, la satisfacción y retención de los desarrolladores mejoran cuando los equipos eliminan la fricción recurrente. fastlane ayuda en un punto muy específico del ciclo de vida: la transición de "la compilación pasó" a "la liberación está fuera de la puerta".
- Por qué los equipos lo mantienen: Convierte los pasos de liberación móviles frágiles en automatización versionada.
- Lo que hay que vigilar: La proliferación de rutas, el manejo de credenciales y la code firma aún necesitan propiedad.
- Mejor comprador: Los equipos que desean una automatización flexible de liberación dentro de una pila de CI/CD existente.
8. Distribución de Aplicaciones de Firebase

La distribución previa es uno de esos lugares donde los equipos se mueven rápidamente o se tropiezan. Si los probadores no pueden obtener las compilaciones fácilmente, la retroalimentación se ralentiza. Si las compilaciones salen sin visibilidad sobre la estabilidad, aprendes demasiado tarde. Distribución de Aplicaciones de Firebase Mantiene ese ciclo simple.
It’s a straightforward way to send iOS and Android builds to testers, especially if the team already uses Firebase services. The integrations with the Firebase console, CLI, Gradle, and fastlane make it easy to wire into an existing release pipeline.
Lo mejor para la distribución de beta sin ceremonia adicional
The best thing about Firebase App Distribution is that it doesn’t ask you a inventar un nuevo proceso. Upload a build, notify testers, connect the experience to Crashlytics, and shorten the gap between “we think it’s ready” and “real devices proved otherwise.”
That pairing with crash reporting matters because advanced tooling adoption isn’t only driven by speed. It’s also driven by the need to manage fast-moving change safely. In an aggregated survey summary, 84% of developers use or plan to use AI tools in development, 47.1% use them daily, 66% say their biggest frustration is AI outputs that are almost right, and 45% say debugging AI-generated code takes more time (Resumen de tendencias de desarrollo de Keyhole SoftwareLa distribución de pruebas tempranas más las señales de estabilidad es una forma de capturar ese ‘casi correcto’ code antes de la liberación amplia.
La limitación es clara. Esto no es un sistema de actualizaciones OTA de producción. Ayuda a validar los builds antes de la liberación. No reemplaza las actualizaciones en vivo, los despliegues de producción estagio o el control de características en tiempo de ejecución.
- Compatibilidad: Equipos que ya utilizan Firebase y necesitan bucles de beta rápidos.
- Compatibilidad útil: Crashlytics para retroalimentación de estabilidad temprana.
- No para: Actualización de entrega de producción o gestión de lanzamiento progresivo.
9. Sentry

Una vez que una aplicación está en manos de los usuarios, la experiencia del desarrollador depende de si los ingenieros pueden explicar rápidamente las fallas. Eso es donde Sentry se vuelve valioso. Proporciona a los equipos de móviles informes de errores, rastreo, salud de la versión, perfilado, registros y telemetría de tiempo de ejecución relacionada en un solo lugar.
Para el trabajo móvil, el ángulo de salud de la versión es especialmente útil. Una pista de stack sola rara vez proporciona el contexto completo. Los equipos también necesitan saber si una versión es ampliamente inestable, aislada a un tipo de dispositivo o relacionada con un lanzamiento específico.
Mejor para la visibilidad en tiempo de ejecución después del lanzamiento.
Sentry es la herramienta a la que recurrir cuando el problema ya no es “¿podemos enviar?” sino “¿podemos entender qué se envió?” Los SDKs móviles para iOS, Android y React Native lo hacen relevante en stacks mixtos, y los flujos de alertas y lanzamiento están maduros.
El contrapeso es la facturación basada en eventos. Los equipos necesitan ajustar la muestra, el uso de cuotas y la calidad del señal. Si no lo hacen, la observabilidad se vuelve cara y ruidosa al mismo tiempo, lo que es la peor combinación.
Una extensión práctica es conectar el manejo de incidentes en tiempo de ejecución con la documentación y la automatización de soporte. Si su equipo necesita flujos de trabajo de problemas de aplicación estructurados alrededor de los datos de Sentry, este DocsBot para la integración de Sentry is un ejemplo útil de cómo los equipos pueden operacionalizar el conocimiento de incidentes en lugar de mantenerlo atrapado en la memoria del ingeniero.
- Uso más fuerte: Depuración post-lanzamiento, monitoreo de errores y salud de la liberación.
- Gran ventaja: Buena visibilidad sobre si una liberación es saludable, no solo si ocurrió un error individual.
- Precaución principal: La muestra y la higiene de eventos requieren propiedad activa.
10. LaunchDarkly
Una liberación sale en el tiempo, pero el equipo no está listo para exponerla a todos. Las ventas quieren acceso temprano para unos pocos cuentas. El soporte quiere un interruptor de muerte. La seguridad quiere un registro de auditoría de quién cambió qué. Ese es el punto donde las banderas de características dejan de ser una comodidad y se convierten en infraestructura de liberación.
LaunchDarkly está diseñado para ese escenario. Separa la implementación de la exposición, por lo que los equipos pueden enviar code, desplegarlo gradualmente, dirigir a usuarios específicos y apagar características sin esperar a otro despliegue. En una pila de DX, se ajusta en la capa de control de liberación entre CI/CD y la observabilidad post-lanzamiento.
Mejor para rollouts controlados y interruptores de muerte
The producto es más fuerte cuando varios equipos comparten la responsabilidad de las liberaciones. Los despliegues porcentuales, las reglas de entorno, los segmentos, las aprobaciones y la historia de auditoría dan a los ingenieros, los productores y las operaciones un lugar para coordinar los cambios. Eso importa más en organizaciones más grandes que la bandera en sí misma. La parte dura no es agregar un booleano. La parte dura es mantener la lógica de liberación consistente, visible y reversible.
Existe un costo por ese control. Los equipos pequeños pueden terminar pagando por la gobernanza que no necesitan, y una mala higiene de banderas crea su propio desorden. Las banderas antiguas siguen en su lugar, las reglas de los objetivos crecen en opacidad, y nadie recuerda qué interruptores todavía son seguros para eliminar.
Normalmente recomiendo LaunchDarkly cuando las banderas necesitan propietarios, fechas de vencimiento o rutas de revisión. Antes de eso, una configuración más ligera puede ser suficiente.
- Mejor ajuste: Equipos que ejecutan despliegues por etapas, acceso a características a nivel de cuenta y interruptores de muerte rápida.
- Valor real: Control de liberación con gobernanza, objetivos y auditoría integrados.
- Desventaja principal: Un instrumento y un proceso más de lo que los equipos pequeños suelen necesitar.
Herramientas de experiencia de desarrollador: Comparación de características de los 10 mejores
| Producto | Características principales | Ventajas únicas ✨ | Observabilidad y calidad ★ | Auditorio objetivo 👥 & Precios 💰 |
|---|---|---|---|---|
| 🏆 Capgo | Actualizaciones en vivo de capas web (JS/CSS/recursos/config), paquetes firmados, actualizaciones diferenciales, canales, deshacer | ✨ Reparaciones rápidas sin retrasos en tiendas de aplicaciones; borde global (300+ ciudades); actualizador de código abierto; CI/CD & APIs tipadas | ★★★★★ Registros por dispositivo, métricas de adopción/fallo, historia de versiones, protección automática de deshacer | 👥 Indie → Empresa (fintech, salud); 💰 Envíe 1 arreglo gratuito + prueba de 14 días; planes de empresa |
| Cloud de Capawesome | Actualizaciones en vivo de Capacitor, compilaciones de macOS/Android en la nube, automatización de publicación en tiendas | ✨ Plataforma Capacitor-primera; precios planos predecibles; ruta de migración de Appflow | ★★★★ Canales y actualizaciones diferenciales; telemetría de compilación capacitor-centrada | 👥 Capacitor equipos; 💰 planes con tarifa fija + prueba de 14 días |
| Bitrise | Corredores macOS/Linux hospedados, 400+ pasos de mercado, caché, CodePush administrado (RN) | ✨ Mercado de pasos rico; tipos de máquina múltiples; CI/CD + RN OTA en un proveedor | ★★★★ Registros de construcción, caché, inspecciones de flujo de trabajo | 👥 Equipos móviles; 💰 Pagar por construcción/minuto (pronóstico complejo) |
| Codemagic | Minutos de construcción basados en uso, planes anuales fijos, CodePush hospedado, Capacitor documentos | ✨ Opciones de precios transparentes; fuerte soporte para Flutter; RN OTA hospedado | ★★★★ Rastros de construcción, escalado de OTA hospedado | 👥 Equipos de Flutter & RN; 💰 Planos por minuto o anuales fijos |
| VoltBuilder | Carga de archivo Zip → binarios de iOS/Android listos para almacenar, firma automatizada, subidas a la tienda | ✨ Bajo overhead de configuración; no se requiere Mac para compilaciones de iOS | ★★★ Estado de compilación simple y salidas firmadas | 👥 Pequeños equipos que necesitan compilaciones rápidas de la tienda; 💰 Planes de pago simples |
| Servicios de Aplicación de Expo (EAS) | Compilaciones en la nube, subidas a la tienda, actualizaciones OTA (MAU y ancho de banda) | ✨ Compilaciones OTA más fáciles y en la nube para Expo/RN; documentación madura | ★★★★ Actualizar métricas de MAU y ancho de banda; registros de compilación | 👥 Equipos de Expo/React Native; 💰 Nivel gratuito + opciones de créditos/pagos de empresa |
| fastlane | Canales para compilar, firmar, subir, metadatos, capturas de pantalla; integraciones de CI | ✨ Automatización gratuita y extensible; pegamento de lanzamiento móvil de facto | ★★★ Registros de herramienta de grado (soporte de la comunidad, sin SLA) | 👥 Equipos que automatizan lanzamientos; 💰 Gratis (comunidad) |
| Distribución de Aplicaciones de Firebase | Distribución de pruebas previas, integración con Crashlytics para señales de estabilidad | ✨ Distribución de pruebas gratuita; bucle de retroalimentación estrecho con Crashlytics | ★★★ Retroalimentación de pruebas + señales de crash para betas | 👥 Equipos que utilizan Firebase; 💰 Gratis |
| Sentry | Informes de errores y crash, seguimiento de rendimiento, reproducción de sesión, salud de lanzamiento | ✨ Flujo de trabajo de estabilidad móvil y salud de lanzamiento profundo; cuotas claras | ★★★★★ Tasas de lanzamientos sin errores, seguimiento, perfilación, reproducción de sesión | 👥 Ingenieros móviles y soporte; 💰 Niveles publicados (basados en cuotas) |
| LaunchDarkly | Banderas de características, lanzamientos porcentuales, targeting, SDKs para móvil/servidor | ✨ Detección de empresas de grado empresarial, kill-switches, gobernanza | ★★★★★ Lanzamientos progresivos y métricas | 👥 Empresas que necesitan control de características; 💰 Precios basados en MAU/servicio (escalables) |
Construyendo tu pila de DX
El error que veo más a menudo es comprar herramientas de experiencia del desarrollador una por una sin decidir qué punto de fricción importa. Un equipo dice que necesitan “mejor DX”, luego acaba con una consola, un proveedor de CI y un sistema de banderas, mientras que el problema subyacente era que las correcciones de errores tardaban demasiado o la propiedad de la liberación era confusa.
Una mejor aproximación es construir una pila alrededor de los puntos de fricción en tu ciclo de vida actual. Para equipos de aplicaciones móviles y de escritorio, esos puntos de fricción suelen aparecer en cinco lugares: confiabilidad de construcción, automatización de liberación, distribución previa a la liberación, observabilidad en producción y control posterior a la liberación. Si uno de esos es débil, el resto de la pila se siente peor de lo que debería.
Pila de desarrollador en solitario
Para un desarrollador en solitario, Capacitor la complejidad es el enemigo. Normalmente no necesitas diez sistemas integrados. Necesitas un camino de liberación que puedas recordar en una noche de viernes cansado.
Mi práctica por defecto sería Capgo, fastlane solo si la automatización de tiendas se vuelve repetitiva, Firebase App Distribution para betas y Sentry para problemas de producción. Esa pila mantiene el bucle cerrado. Construye, prueba, distribuye, monitorea, parchea.
What no funciona bien en esta etapa es comprar la gobernanza de lanzamiento de alta gama demasiado pronto. Si estás enviando una aplicación con un público principal, el manejo de características pesadas y los ajustes de CI altamente personalizados suelen crear más mantenimiento que valor.
Stack de equipo de producto pequeño
Un startup o un equipo de producto pequeño suele necesitar menos hazañas y más consistencia. En este tamaño, un proceso de lanzamiento roto puede bloquear a varias personas al mismo tiempo. El stack debe reducir el costo de coordinación.
Una configuración fuerte aquí es Capawesome Cloud o Codemagic para compilaciones, Capgo para actualizaciones en vivo si estás en Capacitor o Electron, Firebase App Distribution para testers, Sentry para visibilidad de tiempo de ejecución y fastlane donde los pasos de tienda todavía necesitan limpieza. Esa combinación cubre el camino completo desde el commit hasta la retroalimentación de producción sin obligar al equipo a construir herramientas internas demasiado pronto.
En este punto también comienza a importar la disciplina del proceso. Nombra a un propietario para los flujos de trabajo de lanzamiento. Nombra a un propietario para el ruido de observabilidad. Nombra a un propietario para la limpieza de banderas si adoptas el manejo de características. Las herramientas mejoran la experiencia del desarrollador solo cuando alguien atiende el jardín.
Stack de equipo de escalado de móviles
Una vez que tienes varios ingenieros de móviles, ramas de lanzamiento y gerentes de producto que piden lanzamientos etapados, el stack necesita un control de lanzamiento más fuerte. En estas situaciones, Bitrise o Codemagic suele ser más sentido que las utilidades de compilación ligeras, y LaunchDarkly comienza a ganar su costo.
A una configuración práctica es Bitrise para CI/CD, fastlane como pegamento de lanzamiento, Firebase App Distribution para entrega beta, Sentry para salud de lanzamiento, Capgo para Capacitor o actualizaciones en vivo de Electron, y LaunchDarkly para exposición progresiva de características. Cada herramienta tiene un trabajo claro. Esa claridad importa porque la superposición es donde los equipos pierden tiempo.
La advertencia en esta etapa es la proliferación de tableros de control. Si cada herramienta envía alertas y nadie las cura, los desarrolladores dejan de confiar en el sistema. Mejor tener menos señales más agudas. Las mejores pilas de DX son lo suficientemente opinativas como para que los ingenieros sepan dónde buscar primero cuando algo se rompe.
Pila de empresa regulada
Las equipos regulados necesitan los mismos fundamentos, más la auditoría, el control de acceso y las prácticas de lanzamiento más seguras. En fintech, salud y entornos similares, la exigencia no es solo la velocidad. Es la explicabilidad.
Esto empuja la pila hacia herramientas con una gobernanza y visibilidad operativa más fuertes. Capgo es atractivo aquí para actualizaciones en el nivel de la web con paquetes firmados, historia de versiones, guarderías de canal, protección de rollback y registros por dispositivo. Pairlo con una capa de CI/CD madura, Sentry para visión de tiempo de ejecución, LaunchDarkly para exposición de características controlada y fastlane donde la automatización de lanzamiento todavía toca los almacenes de aplicaciones y flujos de firma.
The key design principle for enterprise DX is simple: optimize for reversible change. Teams move faster when they can prove what changed, who received it, how adoption progressed, and how to stop it safely. That is developer experience in the environments where mistakes carry the highest cost.
Las herramientas de experiencia del desarrollador ya no son solo accesorios de productividad. Han pasado a ser la capa de funcionamiento alrededor del propio software. La mejor pila no es la que tiene más logos. Es la que elimina la siguiente fuente real de fricción para tu equipo, y que sigue siendo comprensible seis meses después.
Si tu equipo envía con CapacitorJS o Electron, Capgo es una de las actualizaciones de DX más claras que puedes hacer. Acorta el camino desde la detección de errores hasta la corrección de producción segura, da a soporte y a ingeniería visibilidad compartida de lanzamiento, y mantiene los cambios en la capa web en movimiento sin tener que esperar a la revisión de la tienda.
Sigue adelante desde 10 Herramientas de Experiencia del Desarrollador más destacadas para 2026
Si estás utilizando 10 Herramientas de Experiencia del Desarrollador más destacadas para 2026 para planificar la automatización de CI/CD, conecta con Capgo CI/CD for the product workflow in Capgo CI/CD, Capgo CI/CD, para el flujo de trabajo del producto en Capgo Construcción Nativa, Capgo Integraciones para el flujo de trabajo del producto en Capgo Integraciones, Integración CI/CD para el detalle de implementación en Integración CI/CD, y GitHub Integración de Acciones para el detalle de implementación en GitHub Integración de Acciones.


