Vous remarquez généralement un problème d'expérience développeur au milieu d'une mise à jour. Le CI est bloqué, la signature ne fonctionne que sur un ordinateur portable, un correctif est bloqué par la revue de l'application, et le support ne peut pas déterminer si les utilisateurs rencontrent une ancienne version, une mauvaise mise en production ou un bug de temps d'exécution. Les métriques de sprint ne le capturent rarement aussi tôt. L'équipe le ressent d'abord.
« Les outils d'expérience développeur » couvrent désormais un large éventail de produits au lieu d'un label flou. Les équipes évaluent l'expérience développeur à l'aide de signaux du système et de feedback direct des développeurs, et les fournisseurs se positionnent de plus en plus autour de la télémétrie de flux de travail, des enquêtes et de l'analyse de productivité liée à l'IA extraites de Git, Jira et les systèmes CI/CD. En pratique, la question utile est plus simple : quels outils suppriment la friction de la construction, de la livraison, du débogage, de la mise en production et du retrait de logiciels ?
Cela devient plus difficile pour les équipes de Capacitor et Electron. Les web code sont embarqués dans un enveloppe native, donc la surface opérationnelle s'étend sur l'infrastructure de build, la signature code, la distribution bêta, les mises à jour en ligne, la visibilité des crashs et le contrôle de déploiement. Les transferts de produit, de design et d'ingénierie se dégradent également plus rapidement lorsque la propriété de la mise en production est floue. Si votre équipe est encore en train de resserrer ce processus, ce guide sur les meilleures pratiques de transfert de développeur est à lire en parallèle des choix d'outil dans cet article. Pratiques de transfert de développeur est à lire en parallèle des choix d'outil dans cet article.
La structure ici suit le cycle de vie, et non une classification générique. Les outils de build et de CI appartiennent à un même panier. La livraison et la distribution des mises à jour appartiennent à un autre. L'observabilité et le contrôle des fonctionnalités résolvent un autre type de problèmes. Cette approche rend les compromis plus clairs, et elle conduit à la partie dont ont besoin de nombreuses équipes : les stacks DX opinionnées pour les développeurs solo, les équipes en croissance et les entreprises réglementées.
Table des matières
- 1. Capgo
- 2. Capawesome Cloud
- 3. Bitrise
- 4. Codemagic
- 5. VoltBuilder
- 6. Expo Application Services EAS Build plus EAS Update
- 7. fastlane
- 8. Firebase App Distribution
- 9. Sentry
- 10. LaunchDarkly
- Outils d'expérience de développeur : Comparaison des 10 meilleures fonctionnalités
- Construire votre pile DX
1. Capgo

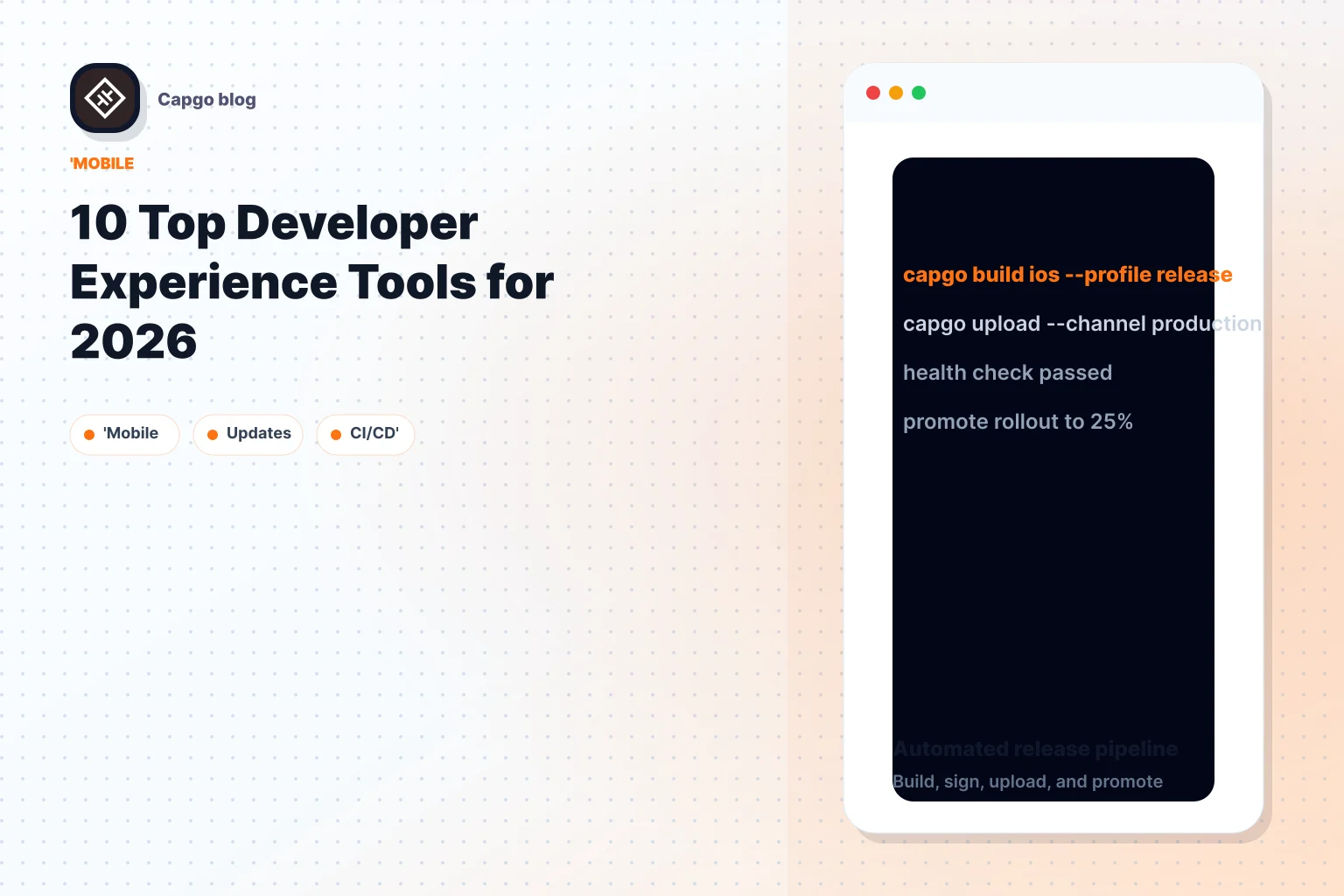
Un bug de production atterrit le vendredi après-midi. La correction vit entièrement dans la couche web, mais l'application reste derrière la revue de magasin. Pour les équipes qui expédient avec Capacitor ou Electron, Capgo raccourcit ce cycle en livrant des mises à jour de JavaScript signé, CSS, config, copie et actifs sans attendre une mise à jour native complète.
That met l'actualisation en direct dans la pile DX, et non dans le CI/CD ou le bucket d'observabilité.
Capgo combine un plugin d'actualisation open source avec un service de livraison hébergé. Les équipes installent le plugin d'actualisation une fois, publient des bundles signés à travers le CLI ou le API, et laissent les clients récupérer les mises à jour à la prochaine lancement. En pratique, les parties utiles sont les contrôles opérationnels autour de ce flux : les canaux, la ciblage de la mise en production, la gestion de la mise à l'arrière, l'historique des versions et les calendriers par appareil qui montrent exactement ce qui s'est passé lors d'une tentative d'actualisation.
Pourquoi Capgo occupe la place d'honneur
Un grand nombre d'outils d'actualisation en direct s'arrêtent à la livraison des bundles. Capgo va plus loin dans les opérations de mise en production. Les journaux par appareil exposent les vérifications, les téléchargements, les installations et les signaux de mise à l'arrière, ce qui donne à l'assistance et à l'ingénierie la même vue lors d'un incident.
Cela compte car les équipes expédient plus vite, souvent avec plus de code généré et plus de volume de mise en production qu'elles n'en avaient il y a un an. La vitesse aide jusqu'à ce qu'une correction presque parfaite atteigne la production. À ce stade, l'outil DX le mieux adapté est celui qui rend la mise à l'arrière et le contrôle de la zone d'impact banal.
Règle pratique : S'il y a la plupart du risque de mise en production dans la couche web, réduisez le temps entre « nous avons trouvé la faille » et « le correctif est sur les appareils ».
The histoire d'automatisation est également solide. Le CLI, API, les interfaces de TypeScript typées, et les intégrations CI s'adaptent aux flux de travail de lancement mobile normal sans beaucoup de 'collage' code. Les mises à jour différentielles gardent les payloads plus petits en envoyant que des fichiers modifiés, ce qui constitue un véritable avantage pour les utilisateurs sur des réseaux plus lents et pour les équipes qui poussent des patchs fréquents.
Où Capgo convient et où il ne convient pas
Capgo convient aux équipes qui ont déjà des pipelines de construction natives et ont besoin d'une façon plus sûre de livrer des mises à jour web après que le binaire est entre les mains des utilisateurs. Les canaux bêta, les déploiements étalés, les flux de diffusion spécifiques aux clients, et les signaux d'adoption et de failure visibles rendent cela utile pour le travail quotidien de lancement, pas seulement pour les réparations d'urgence.
Le compromis est clair. Capgo ne remplace pas les outils de soumission de construction native et de magasin. Les modifications des code, des droits, des SDK, ou des métadonnées de magasin passent toujours par le processus habituel iOS et Android.
Un ou deux points pratiques saillent :
- Meilleure correspondance : Les équipes de CapacitorJS et Electron qui ont besoin de réparations web rapides et de visibilité de lancement claire.
- Contrôles de sécurité solides : Les ensembles signés, la protection de rollback, l'historique de version, et les règles de canal réduisent le risque de déploiement.
- Utile pour le support : Les horloges de dispositif par appareil aident le support et l'ingénierie à déboguer le comportement de lancement à partir des mêmes preuves.
- Principal limitation : Les modifications natives nécessitent toujours la voie standard de l'App Store et du Play Store.
Pour les équipes qui utilisent des outils de cartographie par fonction de cycle de vie, Capgo appartient à la partie post-build, post-release de la pile. Il aide après que CI a terminé et après que l'application est déjà en production, ce qui est exactement là où se manifeste la plupart des douleurs de livraison mobile.
2. Cloud Capawesome

Cloud Capawesome est le type de plateforme que je recommanderais lorsque l'équipe a déjà choisi Capacitor et souhaite moins de parties en mouvement. Il apporte les builds natives, l'automatisation de la publication dans les magasins et les mises à jour en direct dans un seul Capacitor-first setup.
C'est là que se trouve son plus grand avantage. Les fournisseurs CI généraux peuvent gérer Capacitor, mais ils ont souvent besoin de plus de glue, de scripts personnalisés et de maintenance de pipeline. Cloud Capawesome commence par l'hypothèse que Capacitor est le centre du flux de travail, ce qui signifie généralement moins de friction de configuration pour les équipes Ionic et Capacitor.
Meilleur pour les équipes Capacitor qui veulent une plateforme opinionnée unique
L'attrait ici n'est pas la largeur. C'est l'alignement. Si vous migrez d'anciennes outils de livraison d'applications mobiles ou remplacez un flux de travail Appflow, Cloud Capawesome vous donne une route moderne et conçue pour un usage spécifique avec des mises à jour en direct, des canaux, la signature code et les builds cloud sur iOS et Android.
Sa positionnement à tarif fixe plaira également aux équipes qui détestent l'incertitude de facturation basée sur le temps. La prévision des coûts pour le CI mobile peut devenir fastidieuse une fois que les builds parallèles, les retentements et les branches de mise en production commencent à se multiplier. Un modèle de tarification plus simple peut améliorer l'expérience utilisateur en supprimant la friction d'approbation autour de l'utilisation de la pipeline.
Capawesome Cloud est le choix le plus logique lorsque votre équipe veut la standardisation plus que la flexibilité maximale.
L'échange est que c'est plus étroit qu'une plateforme CI/CD large. Si votre pile couvre les services back-end, les applications web et les lancements mobiles sous un seul grand couche d'automatisation, vous préférerez peut-être un fournisseur de pipeline plus général. Mais pour une entreprise Capacitor-lourde, étroit est souvent bon. Étroit signifie moins d'abstractions qui se battent contre le framework.
Une lecture rapide sur le fit :
- Bon choix : Les équipes qui veulent des builds, des publications et des mises à jour en direct étroitement liées à Capacitor.
- Avantage opérationnel agréable : Moins de collage de glue code personnalisé que les CI génériques.
- Avantage budgétaire : La tarification à tarif fixe est plus facile à expliquer internement.
- Inconvénient principal : Si Capacitor n'est pas au centre de la livraison de votre application, la spécialisation compte moins.
3. Bitrise

Bitrise Bitrise a été un nom familier dans le domaine de la CI/CD mobile pour de bonnes raisons. Il comprend les parties peu agréables de la livraison mobile : les exécutants macOS, la signature code, les environnements de construction instables et le fait que les flux de mise en production ne restent rarement simples.
C'est une meilleure option pour les équipes qui ont besoin de pipelines configurables et qui attendent que leur automatisation devienne plus complexe au fil du temps. Les exécutants macOS et Linux hébergés, un grand marché d'étapes et des options de cache de construction donnent aux équipes expérimentées de la place pour ajuster la vitesse et la structure au lieu d'accepter un modèle rigide.
Meilleur pour la CI mobile avec de la place pour personnaliser
Bitrise est le plus fort lorsque votre processus de construction n'est pas juste « exécutez une commande et téléchargez ». De nombreux équipes de produits ont besoin de flux de travail pour la validation des demandes de tirage, la distribution nocturne, les lancements basés sur branch, la génération de captures d'écran, la soumission au magasin et les notifications pour plusieurs applications. Bitrise gère bien cette forme de travail.
La prudence est de prédire les coûts. Une fois que vous travaillez avec des choix de machines, des minutes de construction, des caches et des pipelines parallèles, la plateforme vous donne des leviers utiles mais aussi plus de variables de facturation. Ce n'est pas nécessairement mauvais. Il suffit de dire que finance et ingénierie ont besoin d'une vue plus claire de la consommation.
Seules les outils d'expérience de développeur sont utiles s'ils suppriment la corvée. Un récent bilan discutant DORA et la recherche de Google Cloud fait bien le point : les équipes passent déjà beaucoup de temps sur la dette technique, les interruptions et la coordination, donc l'objectif est de réduire la friction plutôt que d'ajouter un surcoût de mesure (Les méduses lors du choix des outils d'expérience de développeur qui réduisent la corvéeBitrise peut absolument supprimer la corvée, mais seulement si quelqu'un assume la propreté de la chaîne d'exploitation.
- Ce qui fonctionne bien : CI/CD axé sur les appareils mobiles avec de nombreux points d'intégration et flexibilité de flux de travail.
- Ce qui peut mal tourner : Une chaîne d'exploitation personnalisée grandit plus vite que sa documentation.
- Qui devrait l'acheter : Les équipes avec une propriété de libération dédiée ou suffisamment matures pour maintenir des normes de CI partagées.
4. Codemagic

Un problème courant de CI mobile apparaît après les premières sorties. L'équipe a dépassé les builds locaux et les scripts ad hoc, mais elle ne veut toujours pas une plateforme de pipeline qui nécessite une attention constante. Codemagic il s'adapte bien à cette partie du cycle de vie.
Il s'agit d'un outil CI/CD en premier lieu, avec un soutien clair pour Flutter, React Native, et des chemins de travailables pour les Capacitor équipes. Comparé aux systèmes de flux de travail plus lourds, Codemagic demande généralement moins de décisions de plateforme en amont. Cela le rend plus facile à transmettre à une petite équipe de produits qui a besoin de builds réproducibles, de code signatures, d'automatisation de tests et de livraison dans les magasins sans transformer un développeur en administrateur part-time CI.
Idéal pour les équipes qui veulent de la flexibilité dans les tarifs
Le modèle de tarification fait partie de l'attrait. Codemagic propose une capacité de construction basée sur l'utilisation sur macOS, Linux et Windows, et il dispose également de plans annuels fixes pour les équipes qui ont besoin d'un budget plus stable. C'est un compromis pratique, pas une fonctionnalité flashante. Les équipes en phase de démarrage peuvent payer pour l'utilisation réelle, tandis que les équipes plus grandes peuvent réduire les surprises mensuelles qui apparaissent souvent une fois que le volume de lancement augmente.
Son support CodePush hébergé est également utile pour les équipes React Native. La simplification de l'automatisation de la construction et de la livraison OTA sous un seul fournisseur peut simplifier la propriété, surtout si l'équipe est encore en train d'assembler son plus large ensemble de DX à travers CI/CD, mises à jour en direct, distribution et observabilité.
The limitation est dans le champ d'application. Codemagic couvre bien l'automatisation de la construction et de la mise en production, mais elle ne remplacera pas tous les besoins d'actualisation en direct ou de déploiement à travers chaque pile mobile. Si l'équipe a besoin d'une gouvernance d'actualisation plus avancée, d'un contrôle de déploiement étalé ou d'un comportement OTA spécifique à la pile en dehors de React Native, le pairage de Codemagic avec un autre outil peut être plus sensé que de forcer Codemagic à couvrir des tâches pour lesquelles elle n'a pas été conçue.
Je préfère Codemagic pour les équipes qui veulent un modèle opérationnel plus propre qu'un CI personnalisé, mais qui ont besoin de plus qu'une utilité de construction hôte de base.
- Meilleure correspondance : Équipes qui veulent soit des options CI payantes à la consommation, soit des options annuelles fixes.
- Très solide : Les équipes Flutter et les équipes React Native qui veulent une mise en œuvre gérée OTA en plus de l'automatisation de la construction.
- Vigilez à : Des outils supplémentaires si votre processus de mise en production nécessite un contrôle de déploiement plus profond ou une couverture plus large des mises à jour en direct.
5. VoltBuilder

Ne pas chaque équipe a besoin d'une plateforme CI/CD complète. Parfois, l'obstacle est beaucoup plus simple : personne ne veut maintenir un SDK local, et personne dans l'équipe possède un Mac pour les builds iOS. C'est là que VoltBuilder se mérite un rang.
VoltBuilder est plus proche d'une utilité de construction hébergée qu'un système d'automatisation large. Téléchargez le paquet d'application, gérez la signature, obtenez des binaires prêts à être mis en magasin en retour. Pour les petites agences, les anciens magasins Cordova et les projets Capacitor simples, cette simplicité est l'objectif.
Meilleur pour la voie la plus rapide vers des binaires signés
J'aime VoltBuilder lorsque le point de blocage de l'équipe est le surcoût de l'infrastructure plutôt que la sophistication de la chaîne d'outils. Si votre processus de mise en production est encore principalement manuel et que l'application ne justifie pas une plateforme mobile interne complète, un service étroit peut améliorer la DX plus qu'un service puissant.
L'inconvénient est évident. Il ne remplacera pas un niveau d'automatisation mature. Vous ne obtiendrez pas le même type d'orchestration de flux de travail, de modélisation d'environnement ou de profondeur de pipeline de mise en production que vous attendriez d'un fournisseur CI plus large.
Cela ne le rend pas inférieur. Cela le rend focalisé.
- Utilisation forte : Petites équipes qui ont besoin de constructions hébergées iOS et Android avec un minimum de configuration.
- Détail utile : Aucune exigence de Mac pour l'exécution de la construction iOS.
- Limite : C'est pas là où vous construisez une plateforme de mise en production complète avec des flux de travail en branchage et une politique d'automatisation large.
6. Services d'application Expo EAS Build plus EAS Mise à jour

Un goulet d'étranglement React Native commun se présente juste après que la fonctionnalité est prête. Le code est fait, mais obtenir une version de test, pousser une correction et garder les mises à jour de l'application sous contrôle prend encore trop de main levées. Pour les équipes qui construisent déjà autour d'Expo, Services d'application Expo supprime beaucoup de friction dans la phase de mise en production.
EAS Build couvre les builds cloud et la soumission d'applications. EAS Mise à jour gère la livraison hors ligne pour JavaScript et les actifs. Ensemble, ils forment une couche de mise en production ciblée pour la partie de la vie du cycle qui est pourquoi cet outil appartient à la catégorie CI/CD et mise à jour en direct d'un stack DX plutôt qu'à une plateforme mobile générique.
L'appel est clair. Expo a déjà pris une série de décisions de workflow pour vous, et EAS étend ces décisions dans la construction et la livraison. Cela signifie généralement moins de scripts personnalisés, moins de câblage CI et moins de logique de mise en production répartie sur des fournisseurs séparés.
Je le recommande le plus pour les équipes Expo-first qui veulent un service pour gérer les sorties de construction et les mises à jour post-mise en production sans assembler des outils supplémentaires. Les documents sont matures, les valeurs par défaut sont sensées et l'inscription tend à aller plus vite car l'écosystème partage le même modèle mental.
The trade-off is the adaptation to the platform. Les équipes utilisant React Native sans les éléments supplémentaires peuvent toujours obtenir de la valeur à partir de EAS, mais la commodité diminue à mesure que la personnalisation native, les pipelines personnalisés ou les contrôles de mise en production spécifiques à l'organisation augmentent. À ce stade, la décision est moins de savoir si EAS fonctionne et plus de savoir si ses opinions correspondent toujours à la façon dont votre équipe livre du logiciel.
Les coûts nécessitent également une attention. Les crédits de construction, les limites MAU mises à jour et la bande passante peuvent rester raisonnables pour les petites équipes, puis devenir une préoccupation de planification une fois que le volume de mise en production augmente.
- Bon ajustement : Les équipes Expo qui veulent des builds cloud et des mises à jour OTA dans un flux de travail.
- Là où il aide le DX le plus : La cohérence de la mise en production, en particulier pour les équipes qui livrent des mises à jour JavaScript fréquentes.
- Limitation : Plus votre application et votre processus s'éloignent des conventions Expo, plus les décisions de configuration reviennent à votre équipe.
7. fastlane

fastlane se trouve dans la partie de la mise en production automatique d'un stack DX. J'attends de le voir sur les équipes qui veulent que leur processus de mise en production mobile soit défini dans code au lieu d'être enterré dans des listes de vérification, des captures d'écran et la mémoire de quelqu'un sur App Store Connect.
Cela mérite sa place en automatisant les étapes répétitives autour de la signature, des captures d'écran, des métadonnées, de la distribution bêta et de la soumission de magasin. Ce travail est fastidieux, facile à faire faux, et coûteux à interrompre. Un bon Fastfile transforme ces tâches en flux de travail revu que l'équipe peut exécuter de la même manière chaque fois.
Meilleur pour les équipes qui veulent une automatisation de la mise en production qu'elles peuvent contrôler
L'avantage pratique est le contrôle. fastlane fonctionne dans presque n'importe quel CI, y compris GitHub Actions, GitLab CI, Jenkins, Bitrise et Codemagic, afin qu'il s'adapte au pipeline que vous avez déjà au lieu de forcer un changement de plateforme. Pour les équipes qui considèrent l'ingénierie de la mise en production comme partie intégrante du codebase, cela compte.
L'échange est la maintenance. fastlane vous donne beaucoup de liberté, et les voies mal structurées peuvent devenir des légendes de la mise en production avec une syntaxe meilleure. La gestion des secrets, les certificats de signature et la conception des voies nécessitent encore une discipline d'ingénierie. Si personne ne revient sur l'automatisation code avec soin, le pipeline de mise en production dérive comme n'importe autre partie du système.
Je recommande généralement fastlane pour les équipes qui ont dépassé les étapes de mise en production manuelles mais ne veulent pas confier l'ensemble du processus à un service hébergé. C'est particulièrement utile dans les stacks mixtes où CI, test, build et distribution vivent déjà sur plusieurs outils.
« Automatisez les étapes de magasin en premier. Elles brisent la concentration plus que l'étape de compilation ne le fait. »
Les équipes constatent que la satisfaction et la fidélité des développeurs s'améliorent lorsque les équipes suppriment les frictions récurrentes. fastlane aide à un point spécifique du cycle de vie : la passation de main de « le build a réussi » à « le lancement est sorti de la porte ».
- Pourquoi les équipes le gardent : Il transforme les étapes de lancement mobile fragiles en automatisation versionnée.
- Ce à quoi il faut faire attention : La prolifération de lanes, la gestion des identifiants et la code signature nécessitent encore une prise en charge.
- Meilleur acheteur : Les équipes qui veulent une automatisation de lancement flexible à l'intérieur d'un ensemble CI/CD existant.
8. Distribution d'applications Firebase

La distribution pré-lancement est l'un de ces endroits où les équipes se déplacent rapidement ou se blessent. Si les testeurs ne peuvent pas obtenir facilement les builds, la rétroaction ralentit. Si les builds sont envoyés sans visibilité sur la stabilité, vous apprenez trop tard. Distribution d'applications Firebase garde ce cycle simple.
It’s a straightforward way to send iOS and Android builds to testers, especially if the team already uses Firebase services. The integrations with the Firebase console, CLI, Gradle, and fastlane make it easy to wire into an existing release pipeline.
Meilleur pour la distribution bêta sans cérémonie supplémentaire
La meilleure chose à propos de la distribution d'applications Firebase est qu'elle ne vous demande pas de créer un nouveau processus. Téléchargez une build, avertissez les testeurs, connectez l'expérience à Crashlytics, et raccourcissez l'écart entre « nous pensons qu'elle est prête » et « les appareils réels ont prouvé le contraire ».
Ce partenariat avec la détection de crash est important car l'adoption de l'outil avancé n'est pas uniquement motivée par la vitesse. C'est aussi motivée par la nécessité de gérer les changements rapides de manière sécurisée. Dans une synthèse de résumé d'enquête, 84% des développeurs utilisent ou prévoient d'utiliser des outils AI en développement, 47,1% les utilisent quotidiennement, 66% disent que leur plus grande frustration est les sorties AI presque correctes, et 45% disent que la débogage des code générés par AI prend plus de temps (Résumé des tendances de développement de Keyhole SoftwareLa distribution aux testeurs précoce plus les signaux de stabilité est une façon de capturer ce « presque correct » code avant la large diffusion.
La limitation est claire. Il s'agit pas d'un système de mise à jour OTA en production. Il vous aide à valider les builds avant la mise en production. Il ne remplace pas les mises à jour en direct, les déploiements de production étalés ou le contrôle des fonctionnalités en temps de cours.
- Bon ajustement : Les équipes qui utilisent déjà Firebase et qui ont besoin de boucles de bêta rapides.
- Pairage utile : Crashlytics pour les premiers signaux de stabilité.
- Non pour : La gestion de la livraison ou de la mise en production progressive.
9. Sentry

Une fois que l'application est entre les mains des utilisateurs, l'expérience du développeur dépend de la capacité des ingénieurs à expliquer rapidement les échecs. C'est là que Sentry devient précieux. Il fournit aux équipes mobiles des rapports de crash, des traces, de la santé des versions, des profils, des journaux et des métriques de runtime liées dans un seul endroit.
Pour le travail mobile, l'angle de la santé des versions est particulièrement utile. Une trace de pile seule ne fournit rarement le contexte complet. Les équipes ont également besoin de savoir si une version est largement instable, isolée à une classe de dispositif ou liée à une mise en production spécifique.
Meilleur pour la visibilité en temps de cours après la mise en production.
Sentry est l'outil que je consulte lorsque le problème n'est plus « pouvons-nous lancer ? » mais « pouvons-nous comprendre ce qui a été mis en production ? » Les SDK mobiles pour iOS, Android et React Native le rendent pertinent sur des stacks mélangées, et les workflows d'alerte et de mise en production sont matures.
Le compromis est la facturation basée sur les événements. Les équipes doivent ajuster l'échantillonnage, l'utilisation des quotas et la qualité du signal. Si elles ne le font pas, l'observabilité devient coûteuse et bruyante en même temps, ce qui est la pire combinaison.
Une extension pratique est de connecter la gestion des incidents en temps de cours avec la documentation et l'automatisation du support. Si votre équipe a besoin de flux de travail d'application structurés autour des données de Sentry, cela DocsBot pour l'intégration de Sentry is a utile exemple de la façon dont les équipes peuvent mettre en œuvre les connaissances sur les incidents au lieu de les garder prisonnières dans la mémoire des ingénieurs.
- Utilisation la plus forte : La déboguage post-lancement, le suivi des plantages et la santé de la mise en production.
- Avantage principal : Une bonne visibilité sur le fait que la mise en production est saine, et non seulement si une erreur unique s'est produite.
- Précaution principale : La collecte d'échantillons et l'hygiène des événements nécessitent une responsabilité active.
10. LaunchDarkly
Une mise en production est lancée à temps, mais l'équipe n'est pas prête à l'exposer à tout le monde. Les ventes veulent un accès précoce pour quelques comptes. Le support veut un interrupteur d'arrêt. La sécurité veut un journal d'audit pour savoir qui a changé quoi. C'est là que les drapeaux de fonctionnalité cesseront d'être un confort et deviendront une infrastructure de mise en production.
LaunchDarkly est conçu pour cette étape. Il sépare la mise en production de l'exposition, de sorte que les équipes puissent livrer code, les lancer progressivement, cibler des utilisateurs spécifiques et éteindre les fonctionnalités sans attendre un autre déploiement. Dans un stack DX, il s'insère dans la couche de contrôle de la mise en production entre CI/CD et l'observabilité post-lancement.
Meilleur pour les lancements contrôlés et les interrupteurs d'arrêt
La production est la plus forte lorsque plusieurs équipes partagent la responsabilité des mises à jour. Les déroulages de pourcentage, les règles d'environnement, les segments, les approbations et l'historique des audits donnent à l'ingénierie, au produit et aux opérations un seul endroit pour coordonner les changements. Cela compte plus dans les grandes organisations que le drapeau lui-même. La partie difficile n'est pas d'ajouter un booléen. La partie difficile est de maintenir la logique de mise à jour cohérente, visible et réversible.
Il y a un coût à ce contrôle. Les petites équipes peuvent finir par payer pour la gouvernance qu'elles n'ont pas besoin, et une mauvaise hygiène des drapeaux crée son propre désordre. Les anciens drapeaux restent en place, les règles de ciblage deviennent opaques, et personne ne se souvient desquels switches sont encore sûrs à supprimer.
Je recommande généralement LaunchDarkly une fois que les drapeaux nécessitent des propriétaires, des dates d'expiration ou des chemins de revue. Avant cela, un setup plus léger peut suffire.
- Meilleure correspondance : Équipes exécutant des déroulages étalés, des accès au niveau de compte pour les fonctionnalités et des interrupteurs de mise à mort rapides.
- Valeur réelle : Contrôle de mise à jour avec gouvernance, ciblage et auditabilité intégrés.
- Inconvénient principal : Plus d'outil et de processus que les petites équipes ne le nécessitent généralement pas.
Outils d'expérience de développeur : Comparaison des 10 meilleures fonctionnalités
| Produit | Fonctionnalités de base | Points de vente uniques ✨ | Observabilité & qualité ★ | Public cible 👥 & tarifs 💰 |
|---|---|---|---|---|
| 🏆 Capgo | Mises à jour en temps réel du layer web (JS/CSS/actifs/config), ensembles signés, mises à jour différentielles, canaux, annulation | ✨ Réparations rapides sans retard de l'App Store ; édition mondiale (300+ villes) ; metteur à jour open-source ; CI/CD & API de type | ★★★★★ Journalisation par appareil, métriques d'adoption/échec, historique de version, protection automatique de l'annulation | 👥 Indépendant → Entreprise (finance, santé) ; 💰 Expédier 1 correction gratuite + essai gratuit de 14 jours ; plans d'entreprise |
| Cloud Capawesome | Mises à jour Capacitor en temps réel, constructions macOS/Android cloud, automatisation de publication de l'App Store | ✨ Premier plateforme Capacitor ; tarifs prévisibles à taux fixe ; chemin de migration vers Appflow | ★★★★ Canaux & mises à jour différentielles ; métrologie de construction capacitor-centrée | 👥 Capacitor équipes; 💰 forfaits à prix fixe + essai gratuit de 14 jours |
| Bitrise | Exécuteurs macOS/Linux hébergés, 400+ étapes de marché, mise en cache, CodePush géré (RN) | ✨ Marché d'étapes richien; types de machines multiples; CI/CD + RN OTA chez un seul fournisseur | ★★★★ Journal de construction, mise en cache, informations sur les workflows | 👥 Équipes mobiles; 💰 Paiement par minute de construction (prévision complexe) |
| Codemagic | Minutes de construction basées sur l'utilisation, forfaits annuels fixes, CodePush hébergé, Capacitor documents | ✨ Options de tarification transparentes; forte prise en charge de Flutter; RN OTA hébergé | ★★★★ Traces de construction, mise à l'échelle de l'OTA hébergée | 👥 Équipes Flutter & RN; 💰 Forfaits par minute ou annuels fixes |
| VoltBuilder | Téléchargement ZIP → fichiers iOS/Android prêts à l'emploi, signature automatique, téléchargements de magasin | ✨ Faible surcoût de mise en place ; pas de Mac nécessaire pour les builds iOS | ★★★ Statut de build simple & sorties signées | 👥 Petites équipes nécessitant des builds de magasin rapides ; 💰 Plans payants simples |
| Services d'application Expo (EAS) | Constructions cloud, soumissions de magasin, mises à jour OTA (MAU & bande passante) | ✨ Construction OTA + cloud la plus facile pour Expo/RN ; documentation mature | ★★★★ Mise à jour des métriques MAU & bande passante ; journaux de build | 👥 Équipes Expo/React Native ; 💰 Niveau gratuit + options de crédits payants/entreprise |
| fastlane | Voies pour construire, signer, télécharger, métadonnées, captures d'écran ; intégrations CI | ✨ Automatisation gratuite et extensible ; colle mobile de release de facto | ★★★ Journalisation de niveau de tooling (appui communautaire, pas de SLA) | 👥 Équipes automatisant les mises à jour; 💰 Gratuit (appui communautaire) |
| Distribution d'applications Firebase | Distribution de test avant la mise en production, intégration avec Crashlytics pour les signaux de stabilité | ✨ Distribution de test sans coût; boucle de feedback serrée avec Crashlytics | ★★★ Feedback des testeurs + signaux de crash pour les bêta | 👥 Équipes utilisant Firebase; 💰 Gratuit |
| Sentry | Rapports de crash/erreur, suivi de performances, replay de session, santé de la mise en production | ✨ Flux de travail de stabilité mobile et de santé de la mise en production approfondis; quotas clairs | ★★★★★ Taux de crash zéro, suivi, profilage, replay de session | 👥 Ingénieurs mobiles et support; 💰 Niveaux publiés (basés sur des quotas) |
| [LaunchDarkly](https://launchdarkly.com/) | Les drapeaux de fonctionnalités, les déploiements à pourcentage, la ciblage, les SDK pour mobile/server | ✨ Ciblage de niveau entreprise, interrupteurs de déploiement, gouvernance | ★★★★★ Déploiements progressifs & métriques | 👥 Entreprises nécessitant un contrôle de fonctionnalités; 💰 Tarification basée sur le nombre d'utilisateurs actifs/service (échelle) |
Construire votre stack DX
La erreur que je vois le plus souvent est d'acheter des outils d'expérience du développeur un par un sans décider quel point de friction est le plus important. Une équipe dit qu'elle a besoin d'une « meilleure DX », puis se retrouve avec un tableau de bord, un fournisseur de CI et un système de drapeaux, tandis que le problème sous-jacent était que les correctifs rapides prenaient trop de temps ou la propriété de la mise en production était floue.
Une approche meilleure est de construire une stack autour des points de friction de votre cycle de vie actuel. Pour les équipes de développement mobile et desktop, ces points de friction se manifestent généralement en cinq endroits : fiabilité de la construction, automatisation de la mise en production, distribution pré-déploiement, observabilité de la production et contrôle post-déploiement. Si l'un de ceux-ci est faible, le reste de la stack se sent pire qu'il ne devrait.
Stack du développeur solo
Pour un développeur solo Capacitor, la complexité est l'ennemi. Vous n'avez généralement pas besoin de dix systèmes intégrés. Vous avez besoin d'un chemin de déploiement que vous pouvez rappeler une nuit de vendredi fatigué.
Mon choix pratique par défaut serait Capgo, fastlane uniquement si l'automatisation de la mise en magasin devient répétitive, Firebase App Distribution pour les bêta, et Sentry pour les problèmes de production. Cette stack maintient le boucle serrée. Construire, tester, distribuer, surveiller, corriger.
What ne fonctionne pas bien à cette étape est d'acheter une gouvernance de déploiement de niveau entreprise trop tôt. Si vous envoyez une seule application avec une seule audience principale, une gestion lourde des fonctionnalités et des paramètres CI hautement personnalisés créent généralement plus de maintenance que de valeur.
Stack d'équipe de produit petit
Une startup ou une équipe de produit petite a généralement besoin de moins de heroïsmes et plus de cohérence. À cette taille, un processus de déploiement cassé peut bloquer plusieurs personnes à la fois. Le stack devrait réduire les coûts de coordination.
Une bonne configuration ici est Cloudflare Capawesome ou Codemagic pour les builds, Capgo pour les mises à jour en direct si vous utilisez Capacitor ou Electron, Firebase App Distribution pour les testeurs, Sentry pour la visibilité en temps de exécution, et fastlane où les étapes de magasin nécessitent encore des nettoyages. Cette combinaison couvre l'ensemble du chemin de la mise à jour de commit à la feedback de production sans obliger l'équipe à construire des outils internes trop tôt.
C'est également là où la discipline de processus commence à compter. Nommez un propriétaire pour les flux de déploiement. Nommez un propriétaire pour le bruit d'observabilité. Nommez un propriétaire pour la suppression des drapeaux si vous adoptez la gestion des fonctionnalités. Les outils améliorent l'expérience utilisateur uniquement lorsque quelqu'un entretient le jardin.
Stack d'équipe de produit mobile
Une fois que vous avez plusieurs ingénieurs mobiles, des branches de déploiement et des gestionnaires de produit qui demandent des lancements étalés, le stack a besoin de contrôler les déploiements de manière plus forte. Dans ces situations, Bitrise ou Codemagic a tendance à faire plus de sens que les utilitaires de build légers, et LaunchDarkly commence à justifier son coût.
Ainsi, une mise en place pratique est Bitrise pour CI/CD, fastlane comme liaison de mise en production, Firebase App Distribution pour la livraison bêta, Sentry pour la santé de la mise en production, Capgo pour les mises à jour en temps réel de Capacitor ou Electron, et LaunchDarkly pour l'exposition progressive de fonctionnalités. Chaque outil a un travail clair. Cette clarté compte car c'est là que les équipes perdent du temps en raison de chevauchements.
Le warning à cette étape est la prolifération des tableaux de bord. Si chaque outil envoie des alertes et que personne ne les curate, les développeurs cesseront de faire confiance au système. Il vaut mieux avoir moins de signaux plus précis. Les meilleurs stacks DX sont suffisamment orientés pour que les ingénieurs sachent où chercher en premier lorsque quelque chose ne fonctionne pas.
Stack d'entreprise réglementé
Les équipes réglementées ont besoin de tous les mêmes fondamentaux, plus de la traçabilité, du contrôle d'accès et des pratiques de déploiement plus sûres. Dans la fintech, la santé, et des environnements similaires, la exigence n'est pas seulement la vitesse. C'est l'explicabilité.
Cela pousse la pile vers des outils avec une gouvernance et une visibilité opérationnelle plus fortes. Capgo est attractif ici pour les mises à jour de la couche web avec des ensembles de fichiers signés, une histoire de version, des garde-fous de canal, une protection de rollback, et des journaux par appareil. Associez-le à une couche CI/CD mature, Sentry pour une vue d'ensemble de l'exécution, LaunchDarkly pour une exposition contrôlée de fonctionnalités, et fastlane où l'automatisation de la mise en production touche encore les magasins d'applications et les workflows de signature.
The key design principle for enterprise DX is simple: optimize for reversible change. Teams move faster when they can prove what changed, who received it, how adoption progressed, and how to stop it safely. That is developer experience in the environments where mistakes carry the highest cost.
Les outils d'expérience du développeur ne sont plus que des accessoires de productivité. Ils sont devenus la couche de fonctionnement autour de la livraison du logiciel elle-même. La meilleure pile n'est pas celle avec le plus de logos. C'est celle qui supprime la prochaine source réelle de friction pour votre équipe, puis reste compréhensible six mois plus tard.
Si votre équipe expédie avec CapacitorJS ou Electron, Capgo est l'un des améliorations de l'expérience du développeur les plus claires que vous pouvez faire. Cela raccourcit le chemin de la découverte de bogues à la correction de production sécurisée, donne à l'assistance et à l'ingénierie une visibilité de publication partagée, et maintient les modifications de la couche web en mouvement sans attendre la revue de la boutique.
Continuez de 10 Outils d'expérience du développeur les plus élevés pour 2026
Si vous utilisez 10 Outils d'expérience du développeur les plus élevés pour 2026 pour planifier l'automatisation CI/CD, connectez-le avec Capgo CI/CD for the product workflow in Capgo CI/CD, Capgo CI/CD, pour le flux de travail du produit dans les Capgo Rendus natifs Capgo Intégrations pour le flux de travail du produit dans les Capgo Intégrations Intégration CI/CD pour le détail d'implémentation dans l'Intégration CI/CD, et GitHub Intégration d'actions for the implementation detail in GitHub Actions Integration.


