La implementación continua significa todo code cambio que pasa por las barreras de calidad automatizadas previamente se dirige directamente a producción sin un trigger de lanzamiento manual. Aún ahora, solo 45% de las organizaciones automatizan la liberación a producción, lo que explica por qué los equipos que pueden hacer esto de manera segura todavía destacan.
Si estás construyendo con Capacitor o Electron, probablemente hayas sentido la fricción ya. Una corrección de errores está lista, la capa web está parchada, QA está completa, pero la liberación sigue esperando a una persona, una reunión o un ciclo de una tienda de aplicaciones. Esa brecha entre "listo" y "en vivo" es donde la mayoría de las pipelines de entrega se ralentizan.
Para los equipos de móviles, la implementación continua no es solo sobre la automatización del backend. Se trata de separar qué puede enviar automáticamente de qué todavía tiene restricciones de plataforma, y luego diseñar un proceso de liberación que respete ambos. Para las aplicaciones híbridas, eso suele significar un flujo de trabajo para la caja nativa y otro para los activos web con los que interactúan tus usuarios con más frecuencia.
Índice
- ¿Qué es la Implementación Continua?
- CI vs Implementación Continua vs Entrega Continua
- Anatomía de una Pipeline de Implementación Continua
- Elige tu estrategia de despliegue
- La importancia de la observabilidad y los despliegues seguros
- Despliegue continuo para aplicaciones de Capacitor y Electron
- Seguridad y cumplimiento en un mundo de CD
¿Qué es el despliegue continuo?
Un desarrollador integra una corrección de pago en main. La pipeline construye la aplicación, ejecuta comprobaciones automatizadas, valida el resultado y el cambio llega a producción sin que nadie haga clic en “desplegar”. Eso es despliegue continuo.
La definición limpia es sencilla. Continuous deployment is the practice of automatically releasing every code change that passes predefined quality gates directly to production, with no manual approval stepEl cambio que pasa por las barreras de calidad definidas previamente directamente a producción, sin un paso de aprobación manual . La diferencia técnica con el despliegue continuo es simple: el despliegue continuo aún mantiene a un humano en el disparador de producción final. Northflank establece esa distinción claramente en su guía sobre .
despliegue continuo y entrega continua
Cada cambio que pasa se envía. Sin administrador de lanzamientos, sin aprobación nocturna, sin botón “listo para prod”.
For Capacitor teams, this matters because your release surface is split. A native binary may still need store review, but your JavaScript, CSS, content, and config changes can often move through a much faster path. That’s where a practical flujo de CI/CD para aplicaciones Capacitor comienza a parecer menos como un gusto y más como el punto de partida para mantenerse reactivo.
El despliegue continuo también cambia el comportamiento del equipo. Los ingenieros dejan de agrupar reparaciones no relacionadas en una gran versión.
Los gerentes de producto dejan de esperar un “día de lanzamiento.” Los equipos de soporte reciben cambios más pequeños y fáciles de explicar en lugar de regresiones misteriosas de una cesta de actualizaciones de una semana de antigüedad.
CI vs Entrega Continua vs Despliegue Continuo
La mayoría de la confusión proviene del hecho de que los equipos dicen “CI/CD” cuando realmente se refieren a tres niveles diferentes de automatización. Un analogía de fábrica funciona bien aquí. Integración Continua monta las piezas y verifica que el paquete aún se sostenga. Entrega Continua envía el paquete terminado a la plataforma de carga, listo para enviar. Despliegue Continuo
The difference práctica
La respuesta de CI a una pregunta es: ¿se integró el nuevo code limpiamente?
La entrega continua responde a una pregunta diferente: ¿está listo este build para su lanzamiento?
La implementación continua va un paso más allá: si está listo, ¿por qué estamos esperando?
El último paso es donde se muestra la madurez. Un artículo de la industria que cita la Encuesta Global de DevOps de Forrester informa que solo 45%de las organizaciones automatizan el lanzamiento a producción , lo que significa que más de la mitad de las organizaciones todavía mantienen algún paso manual antes de la producción. El mismo artículo coloca esa brecha como la línea divisoria entre la automatización de pipeline ordinaria y la verdadera.
| adopción de implementación continua | Aspecto | Integración Continua (CI) | Entrega Continua (CD) (Entrega Continua) (Implementación Continua) |
|---|---|---|---|
| Main trigger | Code commit o merge | Code commit o merge | Code commit o merge |
| Objetivo principal | Construye y prueba de manera continua | Mantén el software liberado | Lanzar cambios validados automáticamente |
| Lanzamiento en producción | No es el foco | Se requiere un trigger manual | Automático después de que pasen las barreras de calidad |
| Intervención humana | A menudo se necesita más adelante en la cadena de producción | Requerido antes de la producción | Eliminado del paso final de producción |
| Mejor ajuste | Equipos que estabilizan los fundamentos de la ingeniería | Equipos que desean controlar la liberación | Equipos con fuerte automatización y rápida recuperación |
¿Qué siente cada modelo día a día?
CI es el suelo. Si su equipo no puede fusionar de manera segura y obtener retroalimentación de construcción rápida, no hable de despliegue continuo todavía. Entrega continua
is the floor. If your team can’t merge safely and get fast build feedback, don’t talk about continuous deployment yet. Es donde muchos buenos equipos permanecen durante mucho tiempo. Te da construcciones repetibles, validación automática y artefactos listos para producción, mientras se preserva una decisión de liberación humana.
Regla práctica: Si las aprobaciones encuentran regularmente problemas reales, mantén la puerta de control manual. Si las aprobaciones aprueban principalmente construcciones que pasan, la puerta de control puede ser teatro de proceso.
Despliegue continuo hace sentido cuando el costo de esperar es mayor que el riesgo de automatización. Los servicios de backend a menudo alcanzan ese punto antes. Las aplicaciones móviles híbridas pueden alcanzarlo para activos web antes de alcanzarlo para paquetes nativos.
Anatomía de un pipeline de despliegue continuo
Un pipeline que funciona es una cadena de confianza. Una etapa débil convierte “liberación automática” en “incidente automático”.

¿Qué sucede después de una fusión
Un pipeline sólido suele comenzar cuando code se introduce en la rama principal. Desde allí, el sistema debería pasar por una secuencia predecible sin pasos ocultos del operador.
- commit de Code. Una fusión desencadena el pipeline desde GitHub Acciones, GitLab CI, CircleCI o otro ejecutor.
- Construye y prueba. La aplicación compila, las dependencias se resuelven y los tests automatizados se ejecutan.
- Creación de artefactos. La pipeline produce algo inmutable para promocionar, como una imagen de contenedor, un paquete firmado o un conjunto de activos de aplicación empaquetados.
- Despliegue de etapa. El artefacto llega a un entorno que se comporta como producción.
- Validación. Los tests de humo y las comprobaciones de entorno verifican que el despliegue funciona donde se ejecutará.
- Despliegue de producción. Si cada puerta pasa, la liberación sucede automáticamente.
- Monitoreo. El sistema verifica el estado después de que el cambio esté en vivo.
IBM describe la implementación continua como el extremo maduro del espectro CI/CD, donde la validación automática aprobada permite que los cambios se pongan en vivo sin un evento de lanzamiento separado. También señala que esto elimina la necesidad de un día de lanzamiento dedicado y puede poner los cambios en vivo minutos después de que se termine el desarrollo en un resumen de implementación continua de IBM.
Un modelo mental útil para los equipos móviles es que la canalización no termina cuando el comando de despliegue tiene éxito. Termina cuando sabes que la liberación es saludable. Por eso los equipos que estudian prácticas de entrega de software modernas pasan tanto tiempo en la validación y la recuperación como en la velocidad de construcción.
Para un ejemplo práctico móvil, un Capacitor guía de configuración de canalización CI/CD muestra cómo este tipo de flujo se puede integrar en un proceso de entrega de aplicaciones.
Una breve guía de paso ayuda si quieres ver el flujo visualmente:
Por qué importa la confianza en la automatización
La parte dura no es construir las etapas. La parte dura es confiar en ellas lo suficiente para eliminar la pausa humana antes de la producción.
¿Qué funciona:
- Pruebas unitarias y de integración rápidas que fallan ruidosamente cuando se rompe el comportamiento básico.
- Un entorno de pruebas que refleja el comportamiento de producción real lo suficientemente bien como para detectar problemas de configuración.
- Inmutabilidad de artefactos para que la cosa exacta que se validó es la que se libera.
- Propiedad clara cuando una puerta falla. Alguien arregla ahora el pipeline, no en la próxima sprint.
Lo que no funciona:
- QA manual como la puerta efectiva mientras el pipeline pretende ser automático.
- Pruebas de suites de larga duración que entrenan a los desarrolladores para eludir las comprobaciones.
- Desplazamiento de entorno entre la etapa de pruebas y la producción.
- Últimos scripts de shell que se ejecutan justo antes de la publicación. conocidos solo por un ingeniero de lanzamiento.
Elegir tu estrategia de despliegue.
Enviar automáticamente a producción no significa exponer a todos los usuarios a cada cambio de una sola vez. Una buena estrategia de despliegue es cómo los equipos obtienen la velocidad del despliegue continuo sin asumir riesgos imprudentes.

Estrategias que reducen el radio de explosión.
Diferentes patrones resuelven diferentes problemas.
Despliegue azul-verde mantiene dos entornos. Uno sirve a los usuarios, el otro almacena la nueva versión. Después de la validación, se intercambia el tráfico. Esto es útil cuando necesitas un corte limpio y un camino rápido de regreso.
Despliegue canario envía una pequeña porción de usuarios o tráfico a la nueva versión primero. Si la salud sigue siendo buena, el despliegue se expande. Si no, lo retiras antes de que el problema se propague ampliamente.
Despliegue en rama actualiza instancias en lotes. Es común en entornos de servicios donde reemplazar la capacidad gradualmente es más sencillo que mantener pila de duplicados.
Banderas de características separa el despliegue de la liberación. Code puede llegar a producción mientras la característica sigue apagada hasta que el producto, el soporte o la ingeniería decida exponerla.
Despliegues en fases importan especialmente para aplicaciones móviles y de escritorio. Puedes enviar una compilación o una actualización OTA a usuarios de beta, personal de la empresa o un grupo de clientes específicos primero, y luego ampliar la exposición después de la validación.
Cómo elegir en la práctica
La guía de CI/CD de GitLab destaca un punto clave: la preparación importa más que la terminología. La decisión de eliminar la puerta de producción manual depende de la madurez de tus pruebas, observabilidad y capacidades de rollback, como se menciona en la discusión de GitLab sobre Preparación de CI/CD para el funcionamiento.
Aquí está la versión corta de cuándo cada opción es adecuada:
- Elige azul/verde cuando la inoperatividad es inaceptable y puedes permitirte entornos paralelos.
- Elige canario cuando el cambio afecta lógica de riesgo, flujos de usuario o integraciones externas.
- Elige rodante cuando la simplicidad de la infraestructura importa más que el corte instantáneo.
- Elige banderas de características cuando code está listo antes de que la empresa esté lista.
- Elige lanzamiento de audiencia en fases cuando diferentes grupos de usuarios necesitan diferentes niveles de exposición.
Una estrategia de despliegue es un control de riesgo, no una insignia de sofisticación.
Para Capacitor y aplicaciones de Electron, los lanzamientos en fases y las banderas de características suelen tener más peso. Se ajustan a la forma en que los equipos híbridos envían. Puedes actualizar la capa web compartida rápidamente, exponerla a un canal primero y mantener el lanzamiento más amplio hasta que la telemetría muestre resultados limpios.
La Importancia de la Observabilidad y el Reverso Seguro
La implementación continua sin observabilidad es adivinanza. Puedes automatizar la liberación, pero no puedes automatizar la confianza a menos que el sistema te diga qué pasó después de que la modificación se puso en producción.

Qué ver después de una liberación
La supervisión te dice si un métrica conocida cruzó un umbral. La observabilidad va más allá. Da a los ingenieros suficiente contexto para hacer nuevas preguntas cuando algo extraño aparece en producción.
Normalmente, eso significa vigilar:
- Registros para errores de la aplicación, trabajos fallidos y casos de borde inesperados
- Métricas para latencia, tasas de error, patrones de caída y salud del servicio
- Rastros para solicitudes que se degradan solo después de un camino de implementación específico
Que la visibilidad se conecte directamente a los eventos de despliegue. Cuando un lanzamiento comienza a causar problemas, los ingenieros en llamada necesitan correlacionar el tiempo de inmediato en lugar de buscar a través de sistemas separados. Los equipos que mejoran este flujo de trabajo a menudo toman ideas de herramientas enfocadas en la automatización de la respuesta a incidentes, ya que la recuperación de lanzamientos y el manejo de incidentes se superponen en gran medida en la práctica.
La reversión necesita ser rutinaria
La reversión es donde muchas historias de “despliegue continuo” se rompen. Si la reversión depende del conocimiento tribal, un ingeniero senior que se despierta, o una memoria perfecta de la última versión estable, no estás listo.
Un proceso de reversión usable tiene algunas características:
- Es rápido. Los ingenieros pueden restaurar el último estado bueno en una acción o mediante una regla automatizada.
- Está probado. La reversión no es teórica. El equipo la ha ejercitado en staging o en condiciones de producción controladas.
- Es observable. Puedes confirmar que la versión revertida resolvió el problema.
- Es estático. Puede revertir un servicio, una bandera de característica o un canal de actualización sin deshacer el trabajo no relacionado.
Para los equipos de aplicaciones híbridas, la reversión tiene una importancia adicional porque los usuarios móviles pueden seguir ejecutando una actualización mala hasta que se reinicia o refresca la aplicación. Un plan de reversión basado en canales es a menudo más seguro que una reversión de un solo tamaño para todos. Estrategias de reversión para flujos de trabajo CI/CD se vuelven operativas, no teóricas.
La implementación rápida solo es una ventaja si la recuperación es más rápida que el impacto del usuario.
Implementación Continua para Capacitor y aplicaciones de Electron
Las aplicaciones híbridas necesitan un modelo mental diferente. Si trata una aplicación Capacitor o de Electron como un servicio de backend, perderá los dos tracks de lanzamiento que importan.

Dos pistas de entrega, no una
Una aplicación híbrida tiene un cáscara nativa y una capa web.
La caja de concha nativa incluye el envoltorio de plataforma, plugins, permisos, firmado, y paquete distribuido por tienda. Ese camino sigue las reglas de plataforma nativa. Si cambias nativo code, el comportamiento del plugin, permisos, o detalles de empaque, estás de vuelta en el mundo de compilaciones de aplicaciones, firmado, y presentación de tienda.
La capa web es diferente. Tu HTML, CSS, JavaScript, contenido, y algunas configuraciones pueden moverse en un ciclo mucho más ajustado. Esa es la parte de la aplicación que más equipos de producto cambian constantemente, y es la parte donde la implementación continua crea la ganancia práctica más grande.
Esta división es por qué los equipos de móviles deberían dejar de preguntar “¿Tenemos implementación continua?”, y deberían empezar a preguntar dos preguntas mejores:
- Puedemos automatizar compilaciones nativas y presentaciones de forma confiable?
- Puedemos implementar activos web de forma segura a aplicaciones instaladas?
Para muchos Capacitor equipos, la primera respuesta es “parcialmente.” La segunda puede ser “sí,” si el camino de actualización está diseñado bien.
Un modelo de liberación híbrido práctico
Un modelo de trabajo es como este.
Primera ruta: liberaciones nativas
Usa CI para compilar paquetes de iOS, Android, o escritorio cada vez que cambia la caja de concha. Ejecuta pruebas nativas, pasos de firmado, y automatización de distribución. Mantén este pipeline fuerte, pero no pretender que se comporte como un modelo de implementación web pura.
Segunda ruta: liberaciones de activos web
Cuando el cambio se encuentra en la aplicación web compartida, haga que la construcción CI edite el paquete web, ejecute pruebas, firme el payload de liberación y lo publique en un canal de despliegue como interno, beta o producción. Eso cierra el ciclo para la parte más rápida del aplicativo.
Un patrón de operación típico es:
- Un desarrollador fusiona una corrección web.
- La CI construye los activos web.
- Las pruebas y los controles de validación automatizados pasan.
- El paquete está firmado y publicado en un canal limitado primero.
- La observabilidad confirma una adopción saludable y sin regresiones importantes.
- El mismo paquete se promueve más ampliamente.
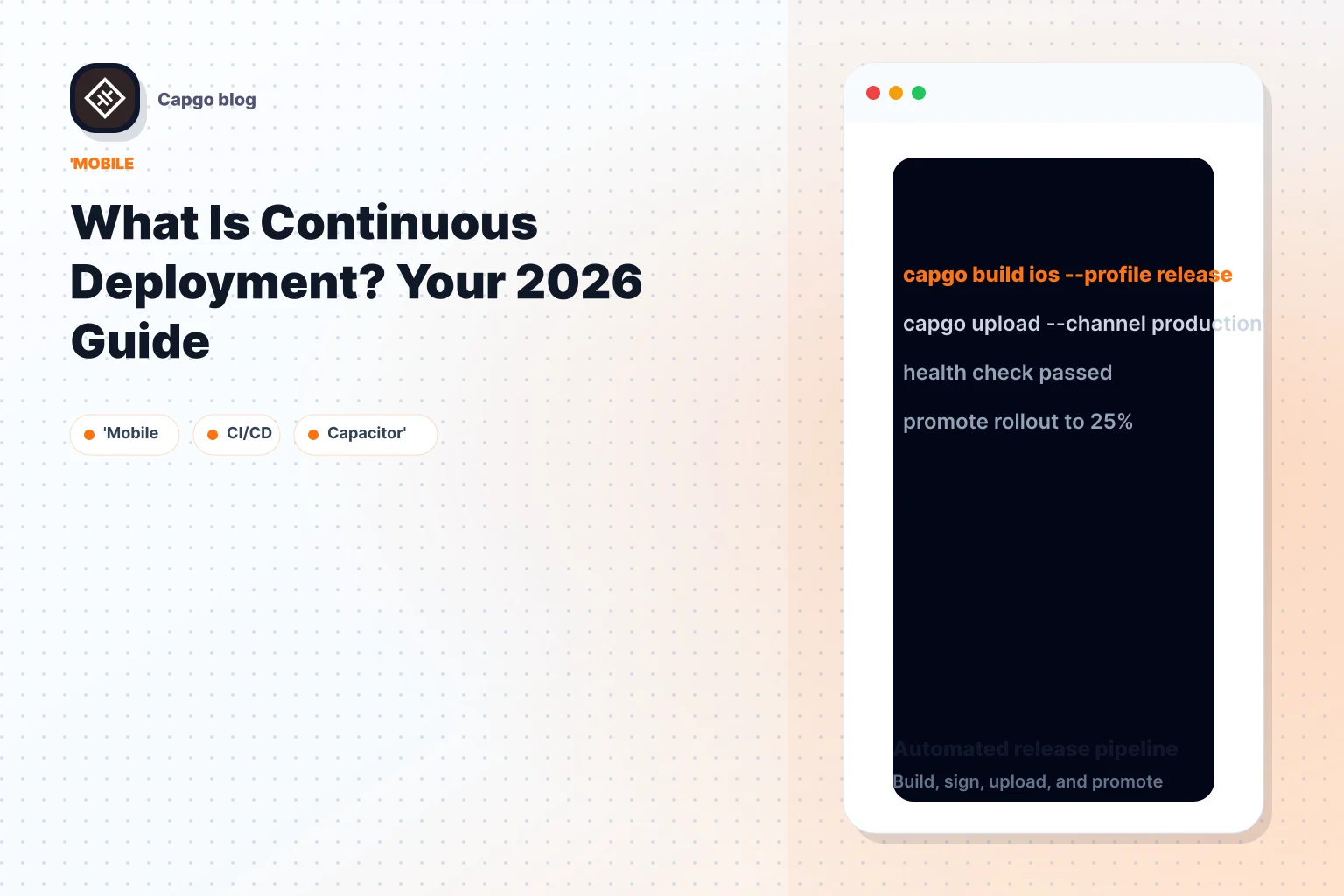
Las plataformas de actualización en vivo se convierten en parte integral de una estrategia de despliegue continuo moderna para aplicaciones híbridas. Manejan la distribución de paquetes web validados a aplicaciones instaladas sin esperar a una liberación nativa completa cada vez. Una opción es Capgo, que proporciona actualizaciones sobre la red firmadas, un despliegue basado en canales, una integración CI/CD y controles de retroceso para Capacitor y flujos de trabajo de Electron.
The detalle operativo que importa no es el nombre del herramienta. Es la disciplina alrededor de los canales, firmas, despliegue en etapas y retroceso. Si su equipo puede enviar un paquete web a cada usuario instantáneamente pero no puede explicar qué versión llegó a qué dispositivo, ha creado velocidad sin control.
Para equipos que integren esto en la automatización, ¿cómo los herramientas CI/CD disparan actualizaciones OTA? es el punto de conexión clave. Su sistema de compilación no debe producir solo artefactos. Debe decidir dónde va la actualización, bajo qué condiciones y cómo recuperarla si es necesario.
Para aplicaciones híbridas, la implementación continua suele significar la implementación continua de la capa web primero y la automatización disciplinada de la capa nativa en segundo lugar.
Seguridad y Cumplimiento en un Mundo CD
Los equipos de seguridad suelen escuchar “lanzamiento automático de producción” y asumir que el riesgo aumentó. En la práctica, una pipeline bien construida puede mejorar el control porque reemplaza los pasos humanos no documentados con políticas repetibles.
La entrega rápida todavía puede ser controlada
Una configuración de CD segura empuja las comprobaciones de seguridad más temprano. El análisis estático, la escaneo de dependencias, la firma de artefactos y las comprobaciones de políticas deben estar en la pipeline, no en un desordenado lanzamiento separado. Si un build viola una regla, no debe avanzar.
Este modelo también crea un registro de auditoría más limpio. El repositorio muestra quién cambió qué. El pipeline muestra qué comprobaciones se ejecutaron. El sistema de despliegue muestra qué llegó a producción y cuándo. Eso es usualmente más fácil de defender que un proceso construido alrededor de aprobaciones manuales, mensajes de chat y scripts de lanzamiento compartidos.
Lo que suelen importar los auditores
La mayoría de los auditores no se preocupan por si un humano hizo clic en un botón de despliegue. Se preocupan por si la organización puede demostrar el control.
Eso usualmente se reduce a unas pocas preguntas:
- ¿Se revisó y validó el cambio antes de la liberación?
- ¿Puedes mostrar quién aprobó el code camino o política?
- ¿Puedes probar que el artefacto no se alteró después de la validación?
- ¿Puedes identificar a qué usuarios o canales se envió la actualización?
- ¿Puedes revocar o revertir rápidamente una liberación mala?
Para los equipos de móviles que envían actualizaciones web a aplicaciones instaladas, los payloads firmados, las permisos de canal y la historia de versiones importan mucho. Ese control ayuda a los equipos a satisfacer la revisión de seguridad interna mientras mantiene la entrega rápida. Si ese es tu entorno, Actualizaciones OTA en CI/CD con guardabarreras de seguridad y cumplimiento es el modelo de operación correcto.
Si estás enviando aplicaciones Capacitor o Electron y deseas una forma práctica para desplegar continuamente la capa web con actualizaciones firmadas, canales de lanzamiento, observabilidad y control de rollback, echa un vistazo a Capgo. Se ajusta a la parte de la entrega de aplicaciones híbridas donde los plazos de las tiendas de aplicaciones son demasiado lentos para reparaciones rutinarias.


