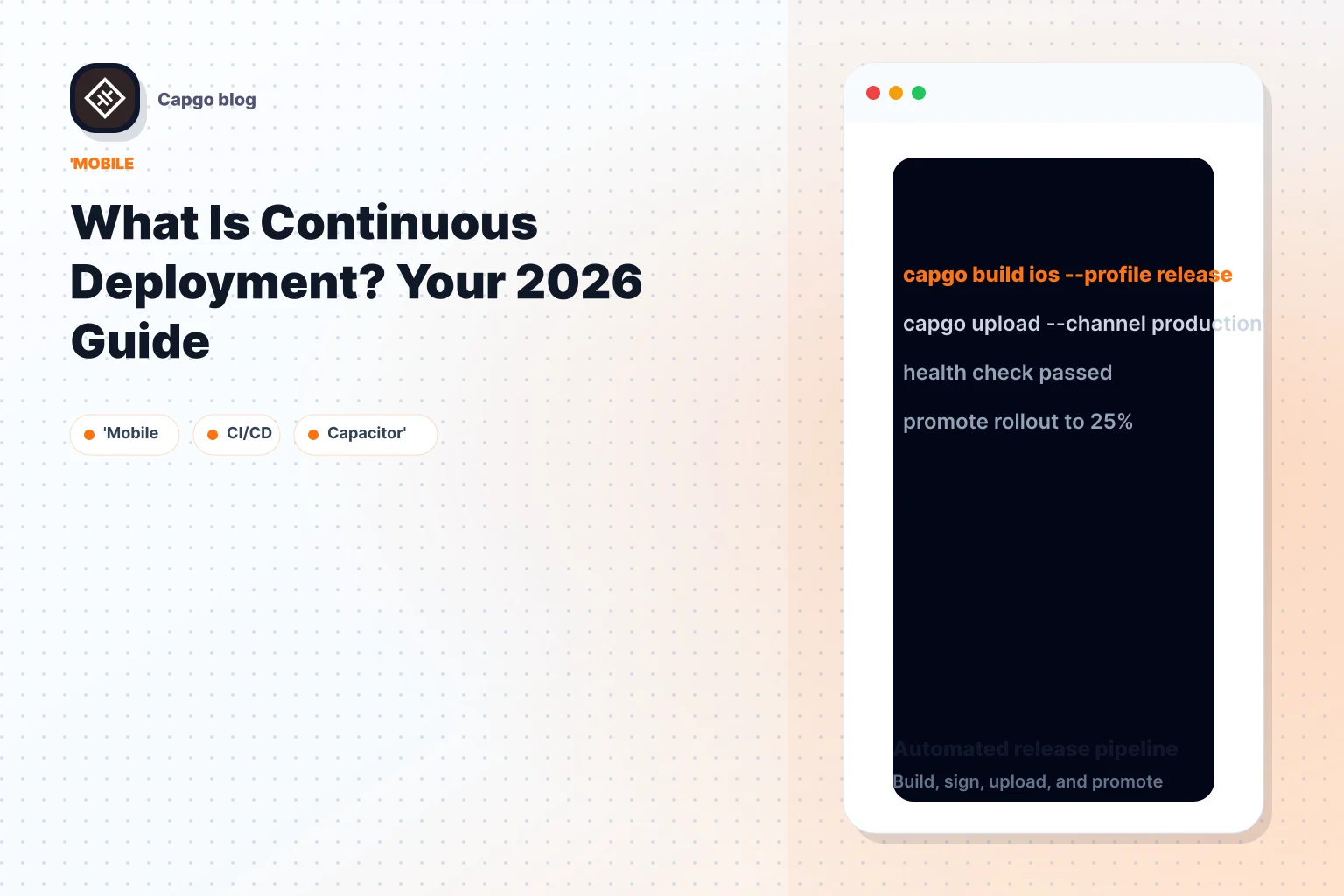
Le déploiement continu signifie chaque code changement qui passe les contrôles qualité automatisés préalables se déplace directement vers la production sans déclencheur de lancement manuel. Même maintenant, seulement 45% des organisations automatisent la mise en production, ce qui explique pourquoi les équipes qui peuvent le faire de manière sûre se démarquent encore.
Si vous construisez avec Capacitor ou Electron, vous avez probablement ressenti la friction déjà. Une correction de bug est prête, la couche web est patchée, la QA est terminée, mais la mise en production attend toujours une personne, une réunion ou un cycle d'application. Cette lacune entre « prêt » et « en ligne » est là où la plupart des pipelines de livraison ralentissent.
Pour les équipes mobiles, le déploiement continu n'est pas seulement question d'automatisation du backend. C'est question de séparer ce qui peut être déployé automatiquement de ce qui a encore des contraintes de plateforme, puis de concevoir un processus de mise en production qui respecte les deux. Pour les applications hybrides, cela signifie généralement un flux de travail pour la coquille native et un autre pour les actifs web que vos utilisateurs interagissent le plus souvent.
Table des matières
- Qu'est-ce que le déploiement continu
- CI vs Déploiement continu vs Livraison continue
- Anatomie d'un pipeline de déploiement continu
- Choisir votre stratégie de déploiement
- L'importance de l'observabilité et des annulations sécurisées
- Déploiement continu pour les applications Capacitor et Electron
- Sécurité et conformité dans un monde de CD
Qu'est-ce que le déploiement continu
Un développeur fusionne une correction de paiement dans main. La pipeline construit l'application, exécute des vérifications automatiques, valide le résultat, et la modification atteint la production sans que personne n'appuie sur « déployer ». C'est le déploiement continu.
La définition propre est simple. Continuous deployment is the practice of automatically releasing every code change that passes predefined quality gates directly to production, with no manual approval stepchange qui passe les portes de qualité prédéfinies directement en production, sans étape d'approbation manuelle . La différence technique par rapport au déploiement continu est simple : le déploiement continu garde encore un humain à la dernière étape de production. Northflank indique clairement cette distinction dans son guide au .
le déploiement continu et le déploiement continu
Tout changement qui passe est expédié. Pas de responsable de la mise en production, pas de vérification tardive, pas de bouton « prêt pour la production ».
Cela ressemble à une approche agressive jusqu'à ce que vous regardiez comment les équipes matures fonctionnent. Elles n'enlèvent pas la dernière porte d'abord. Elles l'enlèvent en dernier, après que la construction est répétitive, les tests sont fiables, les étapes de déploiement sont scriptées, et le comportement de production est visible suffisamment pour attraper rapidement les régressions. Pour les équipes de type Capacitor, cela compte parce que votre surface de mise en production est scindée. Un fichier binaire natif peut toujours nécessiter une revue de magasin, mais vos modifications de JavaScript, CSS, contenu et de configuration peuvent souvent passer par un chemin beaucoup plus rapide. C'est là où une approche flux de CI/CD pour les applications Capacitor commence à ressembler moins à un avantage souhaité et plus à la norme pour rester réactif.
La mise en œuvre continue change également le comportement des équipes. Les ingénieurs cessent de grouper des correctifs non liés dans une seule grande mise à jour. Les responsables de produit cessent d'attendre un « jour de lancement ». Les équipes de support obtiennent des changements plus petits, plus faciles à expliquer au lieu de régressions mystérieuses provenant d'un lot de mises à jour datant d'une semaine.
CI vs Livraison continue vs Déploiement continu
La plupart de la confusion provient du fait que les équipes disent « CI/CD » lorsqu'elles veulent dire trois niveaux différents d'automatisation.
Un analogie de usine fonctionne bien ici. L'intégration continue assemble les parties et vérifie que la construction tient toujours ensemble. La livraison continue place le paquet fini sur le quai de chargement, prêt à être expédié. Le déploiement continu le charge automatiquement sur le camion une fois qu'il a passé l'inspection.
The difference pratique
La CI répond à une question : le nouveau code s'est-il intégré proprement ?
La livraison continue répond à une autre question : est-ce que cette build est prête à être libérée ?
La déploiement continue va encore plus loin : si elle est prête, pourquoi attendons-nous ?
Ce dernier pas est là où la maturité se manifeste. Un article de l'industrie citant l'enquête Forrester sur le Benchmark Global DevOps rapporte que seulement 45% des organisations automatisent la mise en production, ce qui signifie que plus de la moitié des organisations gardent encore une étape manuelle avant la production. L'article en question positionne cette lacune comme la ligne de démarcation entre l'automatisation de pipeline ordinaire et l'adoption réelle Aspect.
| Intégration Continue (CI) | Livraison Continue | Déploiement Continue | Aspect |
|---|---|---|---|
| Détecteur principal | Code commit ou fusion | Code commit ou fusion | Code commit ou fusion |
| Objectif principal | Construire et tester en continu | Maintenir le logiciel en état de sortie | Lancer automatiquement les modifications validées |
| Lancement en production | Pas l'objectif principal | Détecteur manuel requis | Automatique après passage des barrières qualité |
| Intervention humaine | Souvent nécessaire plus tard dans la chaîne de production | Requis avant la production | Supprimé de l'étape de production finale |
| Meilleure correspondance | Équipes stabilisant les bases de l'ingénierie | Équipes qui veulent contrôler les lancements | Équipes avec une forte automatisation et une récupération rapide |
Ce que chaque modèle ressent chaque jour
CI est le plancher. Si votre équipe ne peut pas fusionner en toute sécurité et obtenir des retours rapides sur les builds, ne parlez pas encore de déploiement continu. Déploiement continu
La livraison continue Voilà où de nombreuses équipes de qualité restent longtemps. Cela vous donne des builds répétitifs, une validation automatisée et des artefacts prêts à la production tout en préservant une décision de libération humaine.
Règle pratique : Si les approbations détectent régulièrement des problèmes réels, maintenez la porte de sortie manuelle. Si les approbations valident principalement des builds qui passent, la porte de sortie peut être un théâtre de processus.
Le déploiement continu fait sens lorsque le coût de l'attente est supérieur au risque d'automatisation. Les services back-end atteignent souvent ce point plus tôt. Les applications hybrides mobiles peuvent y parvenir pour les actifs web avant de l'atteindre pour les packages natifs.
Anatomie d'un pipeline de déploiement continu
Un pipeline fonctionnel est une chaîne de confiance. Une étape faible transforme « libération automatique » en « incident automatique ».

Ce qui se passe après une fusion
Un pipeline solide commence généralement lorsque code arrive dans la branch principale. Dès là, le système devrait passer par une séquence prévisible sans étapes cachées de l'opérateur.
- Le commit Code. Une fusion déclenche le pipeline à partir de GitHub Actions, GitLab CI, CircleCI ou un autre exécuteur.
- Build et test. L'application se compile, les dépendances sont résolues et les tests automatisés s'exécutent.
- Création d'artefact. La pipeline produit quelque chose d'immutuable à promouvoir, comme une image de conteneur, un bundle signé ou un ensemble d'actifs d'application empaquetés.
- Déploiement de mise en ligne. L'artefact atterrit dans un environnement qui se comporte comme la production.
- Validation. Les tests de fumée et les vérifications de l'environnement vérifient que le déploiement fonctionne là où il sera exécuté.
- Déploiement de production. Si chaque porte passe, la mise en production se produit automatiquement.
- Suivi. Le système vérifie la santé après que le changement est en ligne.
IBM décrit le déploiement continu comme la fin mature du spectre CI/CD, où la validation automatisée autorise les modifications à être mises en ligne sans un événement de lancement séparé. Il note également que cela supprime la nécessité d'une journée de lancement dédiée et peut mettre les modifications en ligne quelques minutes après la fin de la mise au point dans un vue d'ensemble du déploiement continu de IBM.
Un modèle mental utile pour les équipes mobiles est que la chaîne de production ne s'arrête pas lorsque la commande de déploiement réussit. Elle s'arrête lorsque vous savez que la mise en production est saine. C'est pourquoi les équipes étudiant les pratiques de livraison de logiciels modernes passent autant de temps sur la validation et la récupération que sur la vitesse de construction. Pour un exemple pratique mobile, un
__CAPGO_KEEP_0__ guide de configuration de la chaîne de CI/CD Capacitor CI/CD pipeline setup guide Un guide de passage en revue court peut aider si vous souhaitez voir le flux visuellement :
Pourquoi la confiance dans l'automatisation compte
La partie difficile n'est pas la construction des étapes. La partie difficile est de faire confiance à suffisance pour supprimer la pause humaine avant la production.
Ce qui fonctionne :
__CAPGO_KEEP_0__
- Vérifications rapides et intégrées des unités qui éclatent bruyamment lorsque le comportement de base est cassé.
- Un environnement de pré-production qui reflète le comportement de production réel de manière suffisamment précise pour détecter les problèmes de configuration.
- L'immutabilité des artefacts afin que la chose exacte que vous avez validée soit la chose que vous lancez.
- L'attribution claire lorsqu'une barrière échoue. Quelqu'un fixe maintenant le pipeline, et non la prochaine itération.
Ce qui ne fonctionne pas :
- La QA manuelle comme la barrière effective tandis que le pipeline prétend être automatisé.
- Les suites de tests longues Les développeurs formés pour contourner les vérifications.
- Drift de l'environnement entre l'étape de test et la production.
- Les scripts shell de dernière minute connus uniquement d'un ingénieur de lancement.
Choisir votre stratégie de déploiement
Le déploiement automatique vers la production ne signifie pas exposer tous les utilisateurs à chaque changement en même temps. Une bonne stratégie de déploiement est la façon dont les équipes obtiennent la vitesse du déploiement continu sans prendre de risques imprudents.

Les stratégies qui réduisent le rayon d'impact
Différents modèles résolvent différents problèmes.
Déploiement bleu-vert garde deux environnements. L'un sert les utilisateurs, l'autre conserve la nouvelle version. Après validation, le trafic est redirigé. Cela est utile lorsque vous avez besoin d'une coupure nette et d'une voie rapide de retour.
Déploiement canari envoie une petite tranche d'utilisateurs ou de trafic vers la nouvelle version en premier. Si la santé reste bonne, la mise à l'échelle s'élargit. Si ce n'est pas le cas, vous le retirez avant que l'incident ne se propage largement.
Déploiement en roulis met à jour les instances par lots. C'est courant dans les environnements de services où remplacer progressivement la capacité est plus simple que de maintenir des stacks dupliqués.
Drapeaux de fonctionnalité sépare le déploiement de la mise en production. Code peut atteindre la production tandis que la fonctionnalité reste éteinte jusqu'à ce que le produit, le support ou l'ingénierie décide de l'exposer.
Déploiements étalés sont importants surtout pour les applications mobiles et de bureau. Vous pouvez envoyer une mise à jour ou une mise à jour OTA aux utilisateurs bêta, au personnel interne ou à un groupe de clients spécifique en premier, puis élargir l'exposition après validation.
Comment choisir en pratique
La guidance de CI/CD de GitLab met en avant un point clé : la préparation compte plus que la terminologie. La décision de supprimer la porte de production manuelle dépend de la maturité de vos tests, de votre observabilité et de vos capacités de retrait, comme le note la discussion de GitLab sur Préparation opérationnelle de CI/CD.
Voici la version courte de quand chaque option convient :
- Choisissez bleu/vert lorsque la disponibilité est inacceptable et que vous pouvez vous permettre des environnements parallèles.
- Choisissez canari lorsque la modification touche des logiques risquées, des flux d'utilisateur ou des intégrations externes.
- Choisissez roulant lorsque la simplicité de l'infrastructure compte plus que la mise en œuvre instantanée.
- Choisissez des drapeaux de fonctionnalité lorsque code est prêt avant que l'entreprise ne soit prête.
- Choisissez une mise en production progressive lorsque différents groupes d'utilisateurs ont besoin de différents niveaux d'exposition.
Une stratégie de déploiement est un contrôle de risque, pas un signe de sophistication.
Pour les applications Capacitor et Electron, les lancements progressifs et les drapeaux de fonctionnalité pèsent généralement le plus lourd. Ils correspondent à la façon dont les équipes hybrides livrent leurs produits. Vous pouvez mettre à jour la couche web partagée rapidement, l'exposer à un canal en premier et différer la mise en œuvre plus large jusqu'à ce que les données de télémétrie soient propres.
L'Importance de l'Observabilité et de la Réversion Sécurisée
La mise en production continue sans observabilité est une supposition. Vous pouvez automatiser la mise en production, mais vous ne pouvez pas automatiser la confiance tant que le système ne vous dit pas ce qui s'est passé après la mise à jour est allée en ligne.

Ce à quoi il faut faire attention après une mise en production
La surveillance vous dit si un métrique connue a franchi un seuil. L'observabilité va plus loin. Elle donne aux ingénieurs suffisamment de contexte pour poser de nouvelles questions lorsque quelque chose d'anormal apparaît en production.
Généralement, cela signifie surveiller :
- Les journaux pour les erreurs d'application, les tâches échouées et les cas d'extrémité inattendus
- Les métriques pour la latence, les taux d'erreur, les modèles de crash et l'état de service
- Les traces pour les requêtes qui se dégradent uniquement après un chemin de déploiement spécifique
That la visibilité doit se connecter directement à vos événements de déploiement. Lorsqu'une mise à jour commence à causer des problèmes, les ingénieurs en charge doivent corrélater l'horloge immédiatement au lieu de chercher à travers des systèmes séparés. Les équipes améliorant ce flux de travail empruntent souvent des idées à des outils axés sur l'automatisation de la réponse aux incidentscar la récupération de la mise à jour et la gestion des incidents se chevauchent fortement en pratique.
La mise à l'arrière-plan doit être routine
La mise à l'arrière-plan est là où beaucoup de « histoires de déploiement continu » se cassent. Si la mise à l'arrière-plan dépend de la connaissance tribale, d'un ingénieur senior qui se réveille, ou d'une mémoire parfaite de la dernière version stable, vous n'êtes pas prêt.
Un processus de mise à l'arrière-plan utilisable a quelques traits :
- C'est rapide. Les ingénieurs peuvent restaurer l'état bon le dernier en une action ou par une règle automatisée.
- C'est testé. La mise à l'arrière-plan n'est pas théorique. L'équipe l'a exercée en environnement de test ou en conditions de production contrôlées.
- C'est observable. On peut confirmer que la version rétablie a résolu le problème.
- C'est scoping. Vous pouvez annuler un service, un flag de fonctionnalité ou un canal d'actualisation sans annuler les travaux non liés.
Pour les équipes d'applications hybrides, l'annulation a une importance supplémentaire car les utilisateurs mobiles peuvent continuer à exécuter une mise à jour défectueuse jusqu'à ce que l'application soit redémarrée ou rafraîchie. Un plan d'annulation basé sur les canaux est souvent plus sûr qu'une réversion à la une. Les stratégies d'annulation pour les flux de travail CI/CD deviennent opérationnelles, pas théoriques. Un déploiement rapide n'est qu'un avantage si la récupération est plus rapide que l'impact sur l'utilisateur.
Déploiement continu pour les applications __CAPGO_KEEP_0__ et Electron
Les applications hybrides nécessitent un modèle mental différent. Si vous traitez une application Capacitor ou Electron comme un service backend, vous manquerez les deux pistes de mise à jour qui comptent.
Un diagramme illustrant le flux de déploiement continu pour les applications mobiles et de bureau hybrides en utilisant Capacitor et Electron.

Une application hybride a
un noyau natif un noyau natif et un couche web.
Le shell natif comprend le wrapper de plateforme, les plugins, les droits, la signature et le paquet distribué par magasin. Cette voie suit toujours les règles de la plateforme native. Si vous modifiez la code native, le comportement du plugin, les permissions ou les détails de packaging, vous êtes de retour dans le monde des builds d'applications, de la signature et de la soumission au magasin.
La couche web est différente. Votre HTML, CSS, JavaScript, contenu et certaines configurations peuvent souvent suivre un cycle beaucoup plus serré. C'est la partie de l'application que les équipes de produits changent souvent et c'est la partie où le déploiement continu crée le plus grand gain pratique.
C'est pourquoi les équipes mobiles devraient cesser de demander « Pouvons-nous avoir un déploiement continu ? » et commencer à se poser deux meilleures questions :
- Pouvons-nous automatiser les builds natifs et les soumissions de manière fiable ?
- Pouvons-nous déployer continuellement des actifs web de manière sûre dans les applications installées ?
Pour beaucoup d'équipes Capacitor, la première réponse est « en partie ». La deuxième peut être « oui », si le chemin d'actualisation est bien conçu.
Un modèle de déploiement hybride pratique
Un modèle fonctionnel ressemble à ceci.
Premier chemin : déploiements natifs
Utilisez la CI pour construire des packages iOS, Android ou desktop chaque fois que le shell change. Exécutez les tests natifs, les étapes de signature et l'automatisation de la distribution. Gardez ce pipeline solide, mais ne faites pas croire qu'il se comporte comme un modèle de déploiement web pur.
Deuxième chemin : publications d'actifs web
Lorsque le changement se trouve dans l'application web partagée, laissez la CI construire le paquet web, exécuter les tests, signer le payload de publication et le publier dans un canal de déploiement tel que interne, bêta ou production. Cela ferme le cycle pour la partie la plus rapide de l'application.
Un modèle d'opération typique est :
- Un développeur fusionne une correction web.
- La CI construit les actifs web.
- Les tests et les vérifications automatiques passent.
- Le bundle est signé et publié dans un canal limité en premier.
- La conformité de l'observabilité et l'absence de régressions majeures confirment une adoption saine.
- Même le même bundle est promu plus large.
Les plateformes d'actualisation en direct deviennent une partie intégrante d'une stratégie de déploiement continu moderne pour les applications hybrides. Elles gèrent la distribution de paquets web validés aux applications installées sans attendre une mise à jour native complète chaque fois. Une option est Capgo, qui fournit des mises à jour en ligne signées, un déploiement basé sur les canaux, une intégration CI/CD et des contrôles de retrait pour Capacitor et les workflows Electron.
The détail opérationnel qui compte est pas le nom de l'outil. C'est la discipline autour des canaux, des signatures, de la mise en production étape par étape, et du retrait. Si votre équipe peut envoyer un bundle web à chaque utilisateur instantanément mais ne peut pas expliquer quelle version a atteint quel appareil, vous avez créé la vitesse sans contrôle.
Pour les équipes qui branchent cela sur l'automatisation, comment les outils CI/CD déclenchent les mises à jour OTA est le point de connexion clé. Votre système de build ne doit pas produire uniquement des artefacts. Il doit décider où l'update va, sous quelles conditions, et comment vous le récupérez si nécessaire.
Pour les applications hybrides, le déploiement continu signifie généralement le déploiement continu de la couche web en premier, et l'automatisation disciplinée de la couche native en second.
La sécurité et la conformité dans un monde CD
Les équipes de sécurité entendent souvent « lancement automatique de production » et supposent que le risque a augmenté. En pratique, une pipeline bien construite peut améliorer le contrôle car elle remplace les étapes humaines non documentées par des politiques répétitives.
La livraison rapide peut toujours être contrôlée
Un setup CD sécurisé pousse les vérifications de sécurité plus tôt. L'analyse statique, la balayage des dépendances, la signature des artefacts, et les vérifications de politique doivent se trouver dans la pipeline, et non dans un éparpillement de lancement séparé. Si une build viole une règle, elle ne doit pas avancer.
Ce modèle crée également un fichier de suivi d'audit plus propre. Le dépôt montre qui a modifié quoi. Le pipeline montre quels contrôles ont été exécutés. Le système de déploiement montre ce qui a atteint la production et quand. Cela est généralement plus facile à défendre qu'un processus construit autour d'approbations manuelles, de messages de chat et de scripts de mise en production partagés.
Ce dont les auditeurs s'inquiètent généralement
La plupart des auditeurs ne s'intéressent pas à savoir si un humain a cliqué sur un bouton de déploiement. Ils s'intéressent à savoir si l'organisation peut prouver le contrôle.
Cela se résume généralement à quelques questions :
- La modification a-t-elle été examinée et validée avant la mise en production ?
- Pouvez-vous montrer qui a approuvé le code chemin ou la politique ?
- Pouvez-vous prouver que l'artefact n'a pas été modifié après la validation ?
- Pouvez-vous identifier les utilisateurs ou les canaux qui ont reçu la mise à jour ?
- Pouvez-vous révoquer ou annuler rapidement une mise en production mauvaise ?
Pour les équipes de mobile qui acheminent des mises à jour web dans des applications installées, les payloads signés, les permissions de canal et l'historique de version sont très importants. Ces contrôles aident les équipes à satisfaire les examens de sécurité internes tout en maintenant la livraison rapide. Si c'est votre environnement, Les mises à jour OTA dans CI/CD avec des garde-fous de sécurité et de conformité est le bon modèle opérationnel.
Si vous expédiez des applications Capacitor ou Electron et que vous souhaitez une méthode pratique pour déployer en continu la couche web avec des mises à jour signées, des canaux de déploiement, des fonctionnalités d'observation et un contrôle de retrait, jetez un coup d'œil à Capgo. Cela convient à la partie de la livraison d'applications hybrides où les calendriers des magasins d'applications sont trop lents pour les corrections de routine.


