您在周五发布了一个热修复。周一,支持团队仍然在听说用户从未接收到它,beta测试者卡在了一个陈旧的捆绑包中,而一个企业客户想知道他们的现场团队正在运行哪个版本。这种情况表明 应用程序更新通知 isn’t a modal. It’s an operating system for release control.
In Capacitor 和 Electron 项目中,通常不是检测更新的难点。难点在于周围的所有事情:决定谁应该看到它,什么时候看到它,如果他们忽略它,更新如何通过 CI/CD 流动,以及滚动部署后收到的哪些监控信息。如果您将更新提示视为 UI 装饰,您会得到噪音的提示、脆弱的发布逻辑和困惑的用户。如果您将它们视为产品生命周期的一部分,您会得到更安全的发布和更平静的支持队列。
目录
为什么您的应用程序更新策略很重要
更新不仅影响维护,还影响留存率
团队经常将更新视为维护任务。修复错误,提示用户,继续。这种思维方式忽视了产品的影响。
推送通知是应用程序安装后可以拉回用户的少数生命周期通道之一。数据总结 Invesp的移动推送通知研究 表明推送通知可以通过 至多88%提高应用程序参与度,并且 选择加入的用户被保留在 对于不更新的用户比例。对于更新策略来说,这很重要,因为每个过时的客户端都是一个可能永远不会看到新功能、修复或合规性变化的用户。
一个弱化的更新流程通常会同时产生三个问题:
- 产品滞后 指的是新功能发布不均匀,导致产品经理从分析数据中读取到混合信号。
- 支持拖延 指的是代理人员需要请求截图、版本号和设备信息才能复制问题。
- 安全漏洞 指的是旧客户端持续与已经更新的API通信。
实践规则: 将更新分发视为发布管理的一部分,而不是在 sprint 结束时的礼貌消息。
存储更新和实时更新解决不同的问题
App Store 和 Play Store 更新仍然很重要。Native 依赖项变化、基于政策的发布、权限变化和二进制级别修复属于此类。但是,商店驱动的更新只是系统的一层,并且由于审查和用户采用在您的直接控制之外,因此它们是慢的。
For Capacitor 和 Electron 应用程序,实时更新覆盖了一个不同的工作范畴。它们适用于不需要重新编译二进制文件的网页包变更,例如 JavaScript、CSS、文本、资产和特性标志。实际上,这意味着您可以分离两个发布问题:
| 发布问题 | 最佳匹配 |
|---|---|
| 是否需要新本机二进制文件? | 存储发布 |
| 是否可以安全地将其作为网页包发布? | 实时更新 |
| 用户是否需要在继续之前知道? | 在应用内通知决策 |
| 是否只有一部分用户需要它现在? | 基于频道的发布 |
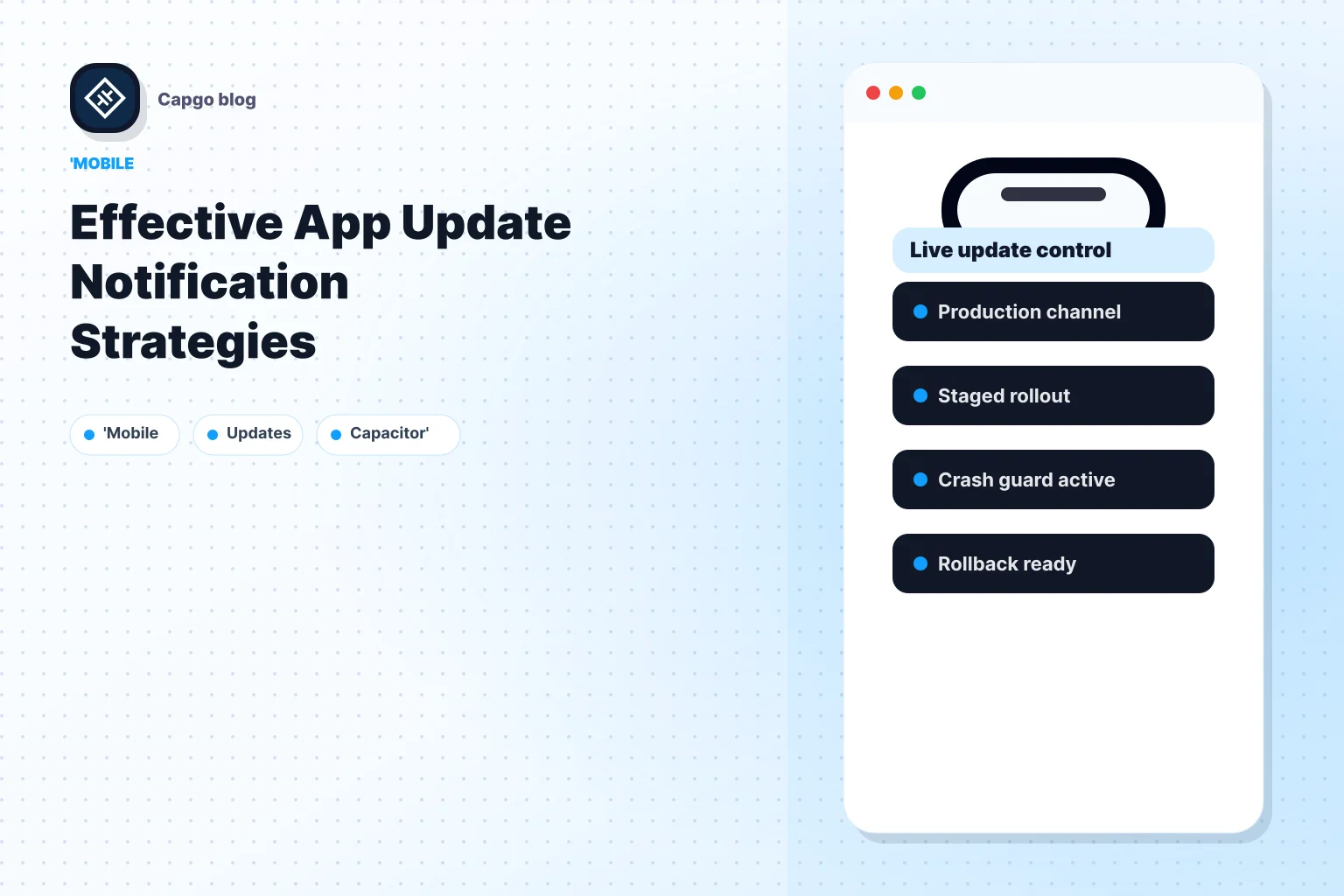
这种分离是为什么机构在构建客户端应用程序时应该停止设计单一“更新可用”弹出窗口的原因。专业团队需要柔和提示、静默应用路径、回滚规则、频道目标和日志,以便支持团队可以后续检查。
信任角度也很重要。用户不在乎更新,反而在乎不可预测的中断。如果应用程序更新顺利,清晰地解释重大变化,并且只有在出现真正的故障或安全风险时才会阻止使用,人们会认为这是专业的表现。
Implementing Update Detection with Capgo
第一个任务很简单:知道用户正在运行哪个版本,属于哪个频道,并决定是否需要下载更新。绝大多数自制更新系统会混乱,因为它们会将这些决策合并在一起。将它们分开是必要的。

从版本意识开始
可靠的更新程序需要在运行时提供三个值:
- 安装的应用程序版本
- 分配的发布频道
- 当前更新状态例如,空闲、检查、可用、下载中、准备就绪、失败
如果您跳过状态模型,通知错误就会迅速出现。应用程序检查太频繁。同一个提示每次启动都会显示。后台下载完成,但 UI 还在显示“检查中”。
通常情况下,使用托管服务是正确的选择,因为操作工作比 code snippt 中建议的要复杂得多。您需要签名的包、频道规则、回滚支持、版本历史、设备级日志和交付基础设施。 Capgo 提供了一个更新插件和托管交付工作流,适用于Capacitor和Electron应用,因此大多数客户端团队都更应该使用它而不是重建内部堆栈。
将更新器连接到应用启动
在应用启动时,运行一个轻量级检查,等待shell准备就绪。除非应用无法继续运行更新,否则不要阻塞首次绘制。
一个典型的Capacitor应用的模式如下:
import { App } from '@capacitor/app'
// import your updater SDK here
type UpdateDecision =
| { kind: 'none' }
| { kind: 'soft'; version: string }
| { kind: 'hard'; version: string }
| { kind: 'silent'; version: string }
async function checkForUpdate(): Promise<UpdateDecision> {
try {
// Replace with your updater SDK call
const result = await updater.check()
if (!result || !result.available) {
return { kind: 'none' }
}
if (result.metadata?.mandatory === true) {
return { kind: 'hard', version: result.version }
}
if (result.metadata?.silent === true) {
return { kind: 'silent', version: result.version }
}
return { kind: 'soft', version: result.version }
} catch {
return { kind: 'none' }
}
}
App.addListener('appStateChange', async ({ isActive }) => {
if (!isActive) return
const decision = await checkForUpdate()
handleUpdateDecision(decision)
})的目的不是“是否有更新”。它是“是否有更新的 check() 适用于 用户 在 这个 频道,并应用程序应该如何响应它”。
一个健康的实现还存储了最后一次成功检查的时间和最后一次提示的版本。这使得应用程序更新通知逻辑变得幂等,而不是烦人的。
读取结果和 branch 早
分支应该尽可能接近检查结果发生。不要在屏幕上散布更新规则。
以下是实际的分离方式:
- 无更新 表示什么也不做,记录正常的检查结果。
- 轻微更新 表示排队一个弹窗、设置徽章或轻量级在应用内提示。
- 静默更新 表示在后台下载并在下一次启动时激活。
- 强制更新 表示将应用切换到受控阻塞流。
在后续的实现中,我喜欢通过一个中央存储来暴露这个决策,以便 React、Vue 或 Ionic UI 可以一致地消费它。
如果您想看到一个 Capacitor 应用的更广泛的设置,这个教程将很有用:
让检测层保持简单。智慧应该在部署策略中,而不是在启动 code 中。
设计有效的通知模式
大多数更新提示失败,因为团队选择了一个模式并将其用于所有内容。这样你就得到了显示阻塞模态来更改复制设置,或者将关键迁移隐藏在没有人注意到的toast后面。
环境已经很拥挤了。 Business of Apps 的 Airshipbenchmark摘要 报告称,平均每天美国智能手机用户收到 46 条推送通知而平均推送反应和点击率仍然很低,分别为 iOS 上的 3.4% 和 Android 上的 4.6% 4.6% on Android. 在应用程序更新通知中,必须赢得用户的注意力而不耗尽用户的注意力。

使用最不具扰乱性的模式仍然有效
一个好的更新UI尊严地考虑了中断的成本。如果用户正在输入付款详细信息、记录患者笔记或扫描库存,一个模态可以比您要修复的错误更糟。
我通常将模式映射为:
- 顶部或底部横幅 用于修复小问题、低紧急性改进和静默更新确认。
- Toast 用于背景状态,例如“下次启动时更新就绪”,但不是用于重要决策。
- 设置或个人资料入口点 用于用户想要控制和查看更改日志的用户。
- 阻塞模态 只有当应用无法在旧版本上安全地继续运行时。
一个细微的横幅通常比一个戏剧性的模态更有效,因为它不强迫用户与界面作斗争。
主要模式的快速比较
| 模式 | 适合 | 主要风险 | 实现注意事项 |
|---|---|---|---|
| 横幅 | 可选更新,低紧急性提示 | 容易忽略 | 每个版本都可以持久地拒绝 |
| 提示 | __CAPGO_KEEP_0__ | 消失得太快了 | 与一个持久的设置项配对 |
| 在应用内消息 | 上下文相关的功能试验 | 可能不会很快被看到 | 将其与相关的屏幕绑定 |
| 模态窗口 | 强制性动作 | 用户的挫折感 | 只保留关键门控 |
最重要的实现细节 状态持久化. 如果用户点击“稍后”,则将该版本存储起来。如果他们dismiss一个横幅,不要在每次路由更改时再次显示它。如果你忘记了这个,用户会认为应用程序已经破裂,即使更新器正在工作。
对于已经使用推送作为其生命周期堆栈的一部分的团队来说,比较应用程序更新的用户体验与更广泛的消息设置是值得的。Capgo的指南 Ionic和Capacitor推送通知与Firebase 有助于将运输问题与要求用户采取行动的应用程序表面分开。
推送仅是故事的一部分
一个常见的错误是假设OS级别的更新徽章和商店通知会为您提供覆盖。实际上,由于设备设置、徽章权限、自动更新行为或电源节省模式,用户经常会错过这些警报。因此,即使商店生态系统正在正确工作时,在应用程序中仍然需要消息。
对于Electron来说,这更为明显。桌面用户通常期望不太突出的状态指示器,而不是模态中断。一个小的“更新准备好”的芯片在壳中可能比系统对话框更专业,后者在工作流程中窃取焦点。
最佳模式是匹配更新的风险和用户当前任务的模式。其他所有内容都是戏剧。
自动化更新流程和用户选择
一旦检测和模式设计就位,核心系统就是工作流程。 在此之内,团队往往要么过度自动化,失去控制,要么欠自动化,导致支持债务。

Coderio 的应用程序维护指南 建议实用的发布节奏是 每 2 到 4 周的微更新 和 每 3 到 6 个月的重大发布,保留硬更新用于 关键安全或稳定性问题。这就是正确的思维模型。决策应该来自发布类型,而不是开发人员的焦虑。
静默更新用于低风险更改
静默更新是Capacitor应用程序中最不被利用的路径。如果您修复了样式、副本、特性标志连接或非破坏性 JavaScript 错误,那么通常没有理由中断用户。
流程很简单:
- 应用程序检查是否有新的捆绑包。
- 如果更新标记为允许在后台应用,则在后台下载。
- 应用程序在下一次启动时激活新的捆绑包。
- 用户可能在重启后看到一条“更新成功”的简短提示,或者什么都没有。
最后的选择取决于更改。如果更新改变了可见的工作流程,则下一次启动时会显示一个小型“新功能”卡片,以帮助用户定位。如果没有,则保持沉默是可以的。
一个简单的状态处理器可能如下所示:
async function handleUpdateDecision(decision: UpdateDecision) {
if (decision.kind === 'silent') {
await updater.download()
await updater.setNextBundle()
localStorage.setItem('pendingUpdateVersion', decision.version)
return
}
if (decision.kind === 'soft') {
showBanner(decision.version)
return
}
if (decision.kind === 'hard') {
showForcedUpdateScreen(decision.version)
}
}可见产品变更的用户选择流程
用户选择流程适用于更新行为足够改变,人们应该选择中断的更新。新导航、修改的引导程序、改变的审批流程或重大仪表板重设计都属于这一类别。
提示应该保持狭窄:
- 发生了什么变化
- 为什么它很重要
- 如果他们现在更新会发生什么
- What happens if they wait
Don’t write release-note poetry into the dialog. One clear sentence and two buttons usually outperform a wall of copy.
I like this pattern:
新版本已发布。它包含了更新的报告工作流程和修复了一个导出问题。现在更新或继续安装后再更新。
使用“稍后”时要谨慎。如果旧客户端仍然有效,让用户继续。如果旧客户端因为API迁移而会中断,不要假装它是可选的。
对于考虑安全运营的团队来说,相同的逻辑也适用于安全自动化。良好的自动化处理日常变化,静默处理安全事件,只有当风险合理时才会升级。这就是为什么这个安全自动化概述对SOC团队有用的原因。它展示了更广泛的设计原则:分类事件、自动化安全路径,并使人类干预成为有意图的行为。 您还可以通过使用逻辑来加紧这个。__CAPGO_KEEP_0__的文章《 应用更新的使用频率分段
You can also tighten this with audience logic. Capgo’s article on 对于狭窄的关键案例,强制更新是必要的 security automation for SOC teams
is useful. It shows the broader design principle: classify events, automate the safe paths, and make human interruption intentional.
强制更新是合法的。它们也很容易被滥用。
在以下情况下使用硬门控:
| 条件 | 强制更新 |
|---|---|
| 已知暴露的安全补丁 | 是 |
| 严重破坏的稳定性问题 | 是 |
| 后端契约的破坏 | 是 |
| UI小修 | 否 |
| 可选功能发布 | 否 |
实现应该明确。检查安装的版本号在启动时,比较它与您的最低支持版本号,如果他们低于阈值,那么只在他们下降时将用户锁定在阻塞状态中。不要从“新版本存在”中推断“强制”。
强制更新屏幕需要三个属性:
- 没有死胡同. 给用户一个明确的重试路径。
- 清晰的说明. 告诉他们为什么需要更新。
- 离线处理. 如果网络不可用,说明也要。
什么不起作用的是一个只有一个“更新”按钮的模态窗口,在脆弱的移动数据上失败而没有任何提示。如果应用程序被阻止,恢复路径必须比正常路径更精致。
高级发布与频道和遥测
大多数更新事件并不是因为检测失败而发生的。它们发生在团队在野外学习更新的行为之前就广泛发布了。
频道减少爆炸半径
基于频道的发布是客户端应用程序中发布实时更新的最安全的方式。相反,向内部、QA、beta、测试、生产或甚至客户特定流的受众发布一个包。
这给你一个看起来更像操作控制而不是二进制发布的发布形状。一个构建可以通过一系列受众移动,各个受众在下一个组看到之前给你信心。
商业发布模型的有用截图,包括更新工作流程周围的计划结构,见下图。

这对通知策略也很重要。 Adapty 的推送通知最佳实践 报告指出 优化的发送时间可以增加反应率 40% 并且 高级目标可以三倍反应率. 在更新系统中,这意味着通道感知的发布和版本特定的消息,而不是对整个安装基数的广泛提示。
Telemetry 告诉您用户是否实际移动
专业的更新系统应该回答这些问题,而不需要工程师通过 ad hoc 日志进行挖掘:
- 每个设备上的哪个捆绑包版本?
- 更新是否下载?
- 是否在下一次启动时成功应用?
- 是否在发布后启动失败率增加?
- 哪些用户仍然卡在过时的版本?
这就是 Telemetry 将更新从发布行为转变为运营过程的地方。没有它,您只知道您发布了什么。有了它,您知道用户采用了什么。
如果支持团队无法看到更新状态,支持团队将升级一个产品问题,实际上是一个发布问题。
我强烈地倾向于每个设备的时间线,而不是仅仅聚合的仪表板。聚合采用曲线是有用的,但它们不会解释为什么一个企业客户在一周后仍然在旧捆绑包上打开应用。
版本目标发布也变得更加实际,当您可以隔离特定人群时。这篇指南在 向用户发送特定版本 这是企业团队通常在支持多个客户环境后需要的控制类型的例子。
CI/CD 应该发布和观察,而不是仅仅构建
现代管道不应该仅仅是“构建成功”。它应该:
- 构建捆绑包
- 签名并将其发布到正确的渠道
- 附加发布元数据
- 监控采用和故障
- 回滚如果健康状况恶化
回滚部分是demo更新器和生产更新器之间的界限。如果捆绑包导致启动崩溃或启动死锁,团队需要快速停止爆炸半径。这种情况是为什么大多数机构使用管理工具而不是DIY的主要原因。交付、防护栏、可观察性和回滚不是次要功能。它们是系统。
CI/CD集成本身不需要复杂。重要的是发布是可预测的和可追踪的。发布应该可以追溯到一个提交、环境、操作者和渠道。如果你不能快速回答这四个问题,事故响应会变得糟糕。
排查常见通知问题
The problems below show up repeatedly in Capacitor and Electron update work. Most of them come from state drift, not from the network.
每次启动时都会出现提示
症状: 用户会忽略应用更新通知,但每次启动应用时都会重新出现。
可能原因: 你已经成功检查了,但并没有持久化提示状态每个版本。
解决方案: 存储用户拒绝或延迟的版本号,并在下次显示 UI 时进行比较。
function shouldPrompt(version: string): boolean {
const dismissed = localStorage.getItem('dismissedUpdateVersion')
return dismissed !== version
}
function dismissPrompt(version: string) {
localStorage.setItem('dismissedUpdateVersion', version)
}这也是团队混淆“可用”和“应该中断”的地方。它们是不同的决定。
静默更新下载但永远不会激活
症状: 日志显示已下载一个捆绑包,但旧 UI 仍在加载。
可能的原因: 应用程序下载了更新,但从未标记为下次启动,或者您的启动路径仍指向最后活动的捆绑包。
解决方案: 使激活明确并在启动时验证它。将“下载”和“活动”视为code和分析中的两个独立状态。
当您将生命周期建模为 available -> downloading -> ready -> active 而不是一个布尔值时,很多bug会消失。
检查在开发和生产环境下表现不同
症状: 更新检测在发布版中有效,但在本地开发环境中无效,或者反之亦然。
可能的原因: 环境特定的配置。不同频道名称、调试时禁用的插件或启动code包裹在错误的守卫中。
解决方案: 让环境行为变得可见。启动时记录日志通道、应用版本和构建模式。不要依赖内存。
- 开发构建 通常应该绕过实时更新检查或指向专用测试通道。
- 测试构建 应该像生产环境一样运行,但在隔离的发布流中运行。
- 生产构建 不应与内部QA流量共享通道。
用户在检查期间离线
症状: 当用户没有网络连接时,应用显示更新状态为损坏。
可能原因: 检查路径假设网络成功,并将失败映射到错误UI而不是中立状态。
解决方案: 在应用程序处于活动状态之前,保持当前版本运行,记录失败的检查,并在应用程序恢复活动时重试。
脱机是正常的运行时状态,而不是异常状态。
对于强制更新,脱机路径需要额外的关注。如果最低支持版本已经过期,应用程序可能需要保持阻塞状态。在这种情况下,请清晰地解释原因,并在网络连接恢复时提供重试操作。如果更新是可选的,永远不要因为暂时的网络丢失而惩罚用户。
所有这些情况的重复原则很简单:分离 检测, 策略, UI,以及 激活。当这些关注点合并到一个钩子或一个屏幕组件时,调试就变成了猜测。
如果您的团队正在发布Capacitor或Electron应用程序,并且需要一个受控的更新系统,具有通道、签名包传递、回滚保护和设备级观察性功能 Capgo 值得评估。它适合那些希望实时更新表现得像发布基础设施而不是手工构建的侧项目的团队。
从有效的应用程序更新通知策略继续
如果您正在使用 有效的应用程序更新通知策略 来规划CI/CD自动化,连接它与 Capgo CI/CD for the product workflow in Capgo CI/CD, Capgo for the product workflow in Capgo Native Builds, Capgo Native Builds for the product workflow in Capgo Integrations, CI/CD 集成 CI/CD 集成的实现细节 GitHub Actions 集成 GitHub Actions 集成的实现细节


